Here is how I have launched a simple but effective data pipeline on AWS just with an EC2 micro instance and one tiny S3 bucket (but behind the scene there are a lot of codes and bash files 😎):
Create a bucket and launch one ec2
0- Go to s3 panel and create a bucket, for example “files-1234”.
1- Launch a t2.micro EC2 instance with Ubuntu OS and name it ETLProject
2- Select instance and then click on Actions > Security> Modify IAM Role. Create a role with admin or read-only access to s3. If you want to transfer files later from ec2 to s3 it’s better to grant admin permission or read-write permission.
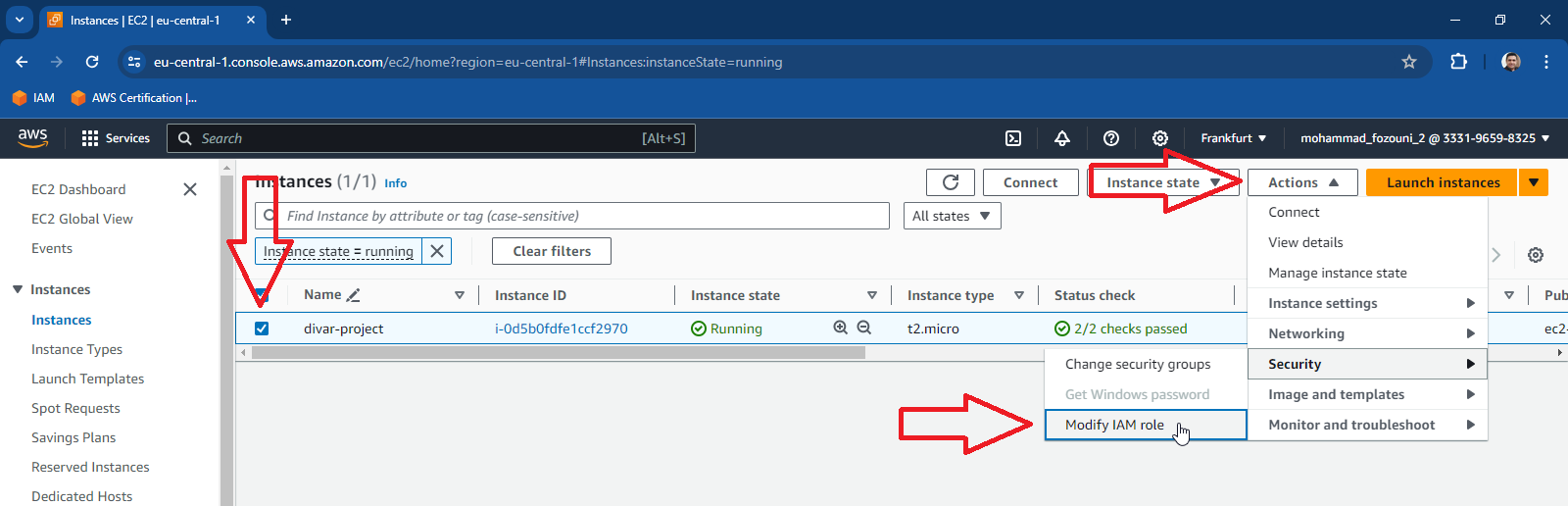
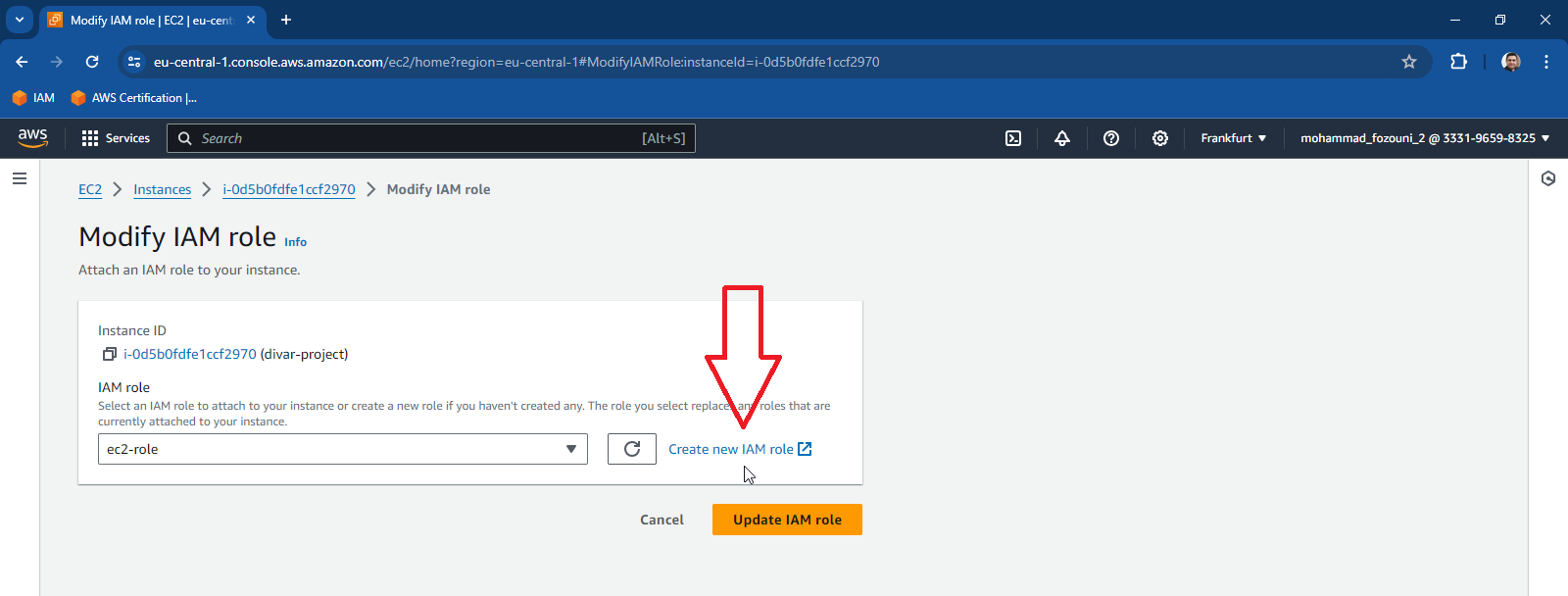
Operations on our PC
3- Connect to it from personal computer cli by running a command like this. First, cd to the directory of ETLProject.pem and then
$ chmod 400 ETLProject.pem
$ ssh -i "ETLProject.pem" ubuntu@ec2-3-71-182-555.eu-east-1.compute.amazonaws.com
Note that “ETLProject.pem” file should be created at the time when we’re launching our instance.
Install required tools
4- Now run these commands to install aws-cli and python
$ sudo apt update
$ sudo apt install python3 pandas
$ sudo snap install aws-cli --classic
Copy files from our PC to aws
5- From our computer’s cli which has been configured by the AWS cli credentials run this command to copy our desired files and scripts to s3
$ aws s3 cp <Fully Qualified Local filename> s3://files-1234
Or
$ for f in *.py; do aws s3 cp $f s3://files-1234; done
Setup cronjobs
6- Since I’m going to schedule a task, I go for cron jobs. So in the instance cli I run
$ sudo usermod -a -G crontab $(whoami)
Copy files from our aws to ec2
7- Then I copy some scripts that are in a s3 bucket to this instance by running:
$ aws s3 cp s3://files-1234/script.py .
$ aws s3 cp s3://files-1234/script.sh .
The above command will be copying the script.py and script.sh to the current directory of my instance
Schedule your job
8- Now schedule your job like this:
$ crontab -e
and then
*/5 * * * * /home/ubuntu/SOME-DIRECTORY/script.sh
That’s it. Now your script will do its job. After one day or one week you can see the results and copy the output again to s3 by
$ aws s3 cp /home/ubuntu/SOME-DIRECTORY s3://files-1234
Or you can write a bash script again to copy the final result for you.