در دنیای امروز، طراحی یک معماری دادهی کارآمد و پایدار، یکی از دشوارترین چالشهاییست که در مسیر مدیریت داده با آن مواجه هستیم. مسیر حرکت داده از لحظهی تولید در سیستمهای منبع تا نقطهی مصرف در تحلیلها و تصمیمگیریهای کلان متأثر از عوامل گوناگونی مانند میزان بلوغ سازمان، حساسیتهای امنیتی و قانونی، ساختار تیمهای فنی، الزامات عملکردی و هزینهای، و ابزارها و زیرساختهای در دسترس میباشد. همین تنوع و پیچیدگی، سبب شده است که هیچ نسخهی یکتایی برای طراحی معماری داده وجود نداشته باشد. با این حال، در قلب هر معماری داده، مفهومی بنیادین نهفته است: تفکیک لایهای.
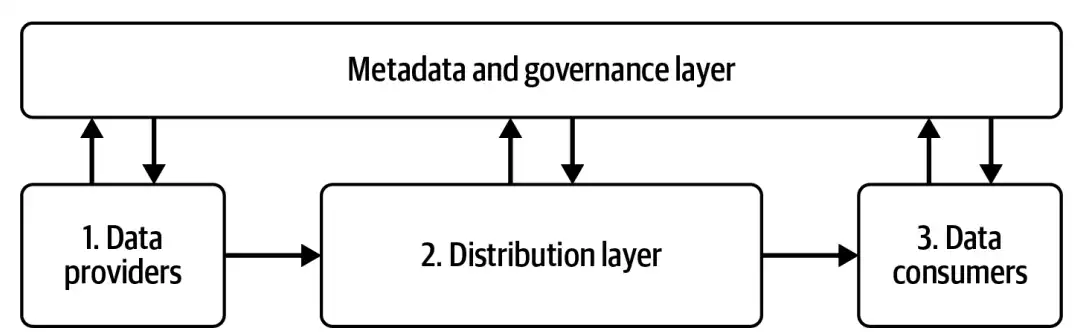
نگاه لایهای به معماری داده، مفهومیست که از سالهای ابتدایی طراحی معماری داده جای خود را بهخوبی در سازمانهای مختلف باز کرده. در سادهترین مدل، این معماری از سه لایهی اصلی تشکیل میشود: لایهی تولیدکنندگان داده (Data Providers)، لایهی توزیع و پردازش (Distribution Layer)، و لایهی مصرفکنندگان داده (Data Consumers). هر یک از این لایهها با چالشها و نیازهای خاص خود همراه است. لایهی اول، با دادههایی ناهمگون از منابع مختلف، ساختارها و فرمتهای متنوع، و در موقعیتهای فنی و سازمانی پراکنده سروکار دارد. لایهی دوم، محل پردازش، پالایش، و مدیریت دادههاست؛ جایی که انتخاب ابزارهای درست و ترکیب آنها از میان صدها راهکار متنباز و تجاری، کاری بسیار ظریف و تعیینکننده است. و لایهی سوم، محل بهثمر نشستن تلاشهاست، مصرف داده برای بینش، پیشبینی، اتوماسیون، و تصمیمگیریهای مبتنی بر واقعیت.
اما این سهلایه، تنها پوستهای کلی از آن چیزیست که در عمل اتفاق میافتد. سازمانهایی که گام در مسیر مدرنسازی معماری دادهی خود میگذارند، بهسرعت درمییابند که این لایهها باید با لایهی مهم دیگری پوشش داده شوند: لایهی فراداده و حاکمیت (Metadata & Governance). بدون وجود سازوکارهای شفاف برای استانداردسازی، امنیت، کیفیت، و نظارت بر جریان داده، هیچ معماری پایداری قابل اتکا نخواهد بود.
در این میان، ظهور معماریهای باز و مبتنی بر ابزارهای متنباز، مانند Spark و فرمتهایی نظیر Delta Lake، باعث شکلگیری تحولی عظیم در ساختارهای سنتی شده است. جایی که پیشتر راهکارهای انحصاری و پرهزینه برقرار بود، امروز سازمانها میتوانند با ترکیب ابزارهایی از دنیای متنباز، معماریای پویا و قابل گسترش بسازند. اما این «modern data stack» در عین انعطاف، با چالشی جدی روبهروست: عدم یکپارچگی ذاتی. هر ابزار، استانداردها، فرادادهها و سازوکارهای تبادل دادهی خاص خود را دارد. همین باعث میشود که پیادهسازی معماری داده با این ابزارها، نیازمند طراحی دقیق، همراستاسازی اجزا، و حل چالشهای سازگاری میان سرویسها باشد، کاری که در بسیاری از موارد، فراتر از توان یا تخصص تیمهای فنی کوچک است.
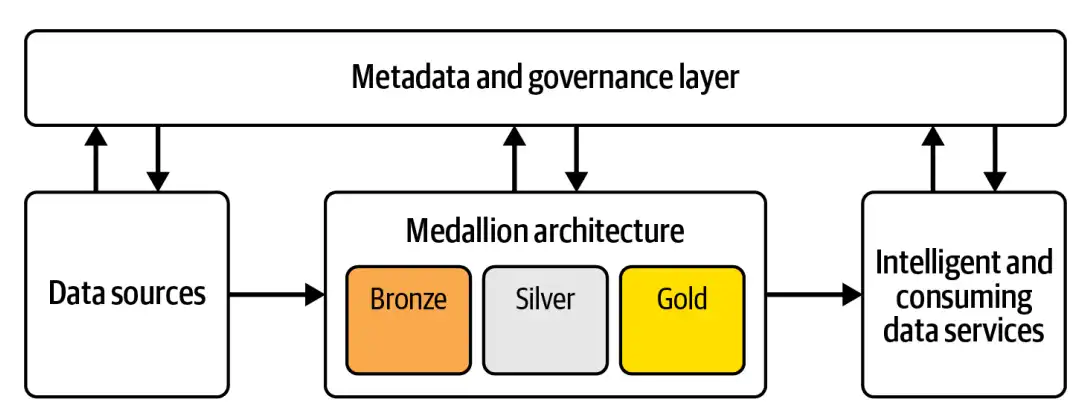
در پاسخ به این چالش، نیاز به چارچوبی شفاف و قابل انطباق بیش از پیش احساس میشود؛ چارچوبی که هم قدرت ساختاردهی داشته باشد و هم ظرفیت رشد و انبساط. در این نقطه است که معماری مدالیون (Medallion Architecture) وارد میشود. آنچه به عنوان معماری مطرح میشود در واقع الگوهای طراحی (data design pattern) معماری داده هست، که بر پایهی لایهبندی تدریجی داده بنا شده و پاسخی مؤثر به نیازهای پیچیدهی معماریهای مدرن است. سه لایهی Bronze، Silver، و Gold در آن، نه تنها داده را بر اساس میزان پالایش و آمادگی دستهبندی میکنند، بلکه راهی شفاف برای تعریف مسئولیتها، بهینهسازی پردازش، و سازگاری با ابزارهای متنوع فراهم میسازند. ترکیب این مدل با توانمندیهای Spark و Delta Lake، باعث شده که معماری مدالیون در بسیاری از سازمانها به عنوان پایهی معماری لیکهاوس (Lakehouse) مدرن شناخته شود، معماریای که قدرت ذخیرهسازی عظیم دیتالیک را با عملکرد و ساختار تحلیلمحور دیتاورهاوس در هم میآمیزد.
معماری مدالیون چیست؟
در قلب بسیاری از معماریهای مدرن داده، بهویژه در زیرساختهای Lakehouse، الگویی ساده اما مؤثر وجود دارد که دادهها را بهصورت مرحلهای و تدریجی پالایش میکند، الگویی طراحی موسوم به معماری مدالیون. این معماری، دادهها را از خامترین حالت تا تحلیلپذیرترین شکل، در سه لایهی منطقی سازماندهی میکند: Bronze، Silver، و Gold. هدف از این لایهبندی، بهبود مستمر کیفیت، ساختار، و ارزش داده در هر مرحله از مسیر پردازش است. در نگاه اول، این سه لایه بهنظر صرفاً برچسبهایی تجاری هستند. اما در عمل، هر یک از آنها نقش دقیق و متمایزی در جریان حیات داده (data lifecycle) ایفا میکند و چارچوبی مشخص برای تیمهای فنی، تحلیلگر، و حتی مدیران کسبوکار فراهم میسازد.
لایهی برونز (Bronze Layer)
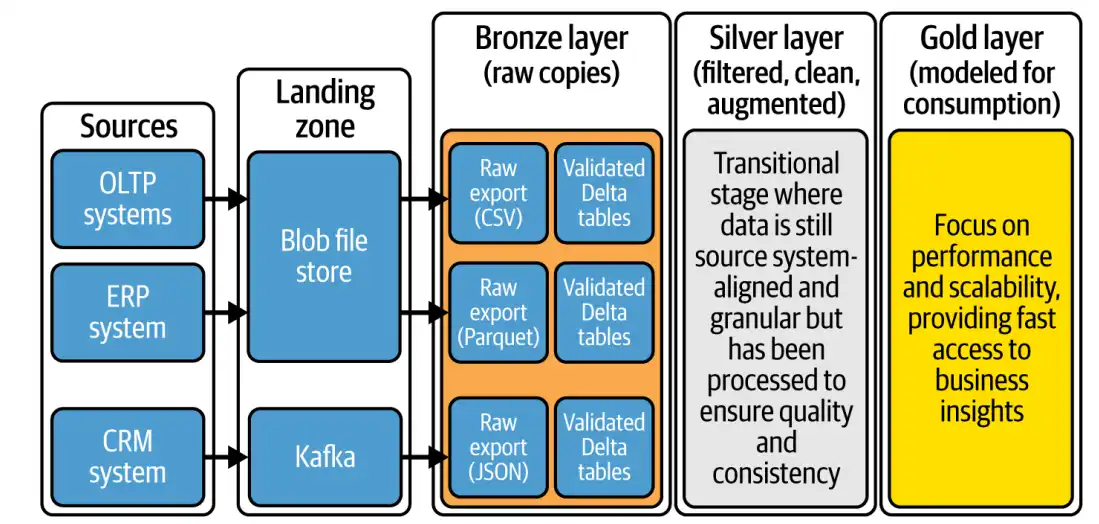
نقطهی شروع مسیر داده، جاییست که اطلاعات به همان شکلی که از سیستمهای منبع (source systems) استخراج شدهاند، بدون دستکاری ذخیره میشوند. این لایه، نقشی آرشیوی دارد و ساختار طبیعی و اصلی داده را حفظ میکند. دادهها ممکن است ناقص، تکراری یا ناسازگار باشند، اما ثبت آنها در این حالت اولیه بهعنوان مرجع تاریخی (source of truth) ضروری است. این لایه تضمین میکند که در صورت نیاز، همواره بتوان به دادهی خام و اصلی رجوع کرد.
لایهی سیلور (Silver Layer)
در این مرحله، دادهها از حالت خام خارج میشوند و بهسوی پالایش حرکت میکنند. این لایه محل اجرای بررسیهای کیفیتی (data quality checks)، حذف تکرارها، نرمالسازی فرمتها، و استانداردسازی دادههاست. خروجی این لایه، دادههایی با ساختاری تمیز، یکدست، و آمادهی اتصال یا تحلیلهای پیچیدهتر است. لایه Silver اغلب همچنان سطح گرانولار (granular) داده را حفظ میکند، اما اطمینان حاصل میشود که دادهها دقیق، همسان، و قابل اتکا هستند.
لایهی گلد (Gold Layer)
در لایهی نهایی، تمرکز از «پالایش» به سمت «ارزشآفرینی» تغییر میکند. دادههای تمیز و آمادهشده از لایهی Silver، اکنون برای نیازهای خاص کسبوکار بهینه میشوند.این مسیر از طریق تجمیع (aggregation)، خلاصهسازی (summarization)، غنیسازی (enrichment)، و مدلسازیهای تحلیلی پیشرفته میسر میشود. این لایه، جاییست که داده به بینش تبدیل میشود و مستقیماً در خدمت تصمیمگیریهای استراتژیک، گزارشگیری سطح بالا، یا کاربردهای هوش تجاری (BI) و یادگیری ماشین قرار میگیرد.
در نگاه کلی، معماری مدالیون الگویی شفاف برای جداسازی مراحل مختلف پردازش داده ارائه میدهد. اما در عمل، بسیاری از سازمانها در فهم عمیق این لایهها، نحوهی پیادهسازی صحیح آنها، و مرزهایشان با چالش مواجهاند. پرسشهایی نظیر:
- دادهها در کدام لایه باید قرار گیرند؟
- چه میزان از پردازش باید در هر لایه انجام شود؟
- چگونه میتوان اجزای این معماری را بهشکل metadata-driven طراحی کرد؟
- نقش حاکمیت داده و اتوماتیک کردن فرآیندها در این لایهبندی چیست؟
این سؤالات نشان میدهند که انتخاب یک پلتفرم یا ابزار مناسب بهتنهایی کافی نیست. آنچه موفقیت معماری مدالیون را تضمین میکند، درک عمیق از هدف، نقش، و مرزهای هر لایه، و پیادهسازی دقیق و همراستای آن با نیازهای واقعی سازمان است.
پیشنیازهای طراحی یک معماری مدالیون مؤثر
پیش از ورود به لایههای اصلی معماری مدالیون (یعنی Bronze، Silver و Gold) ضروری است که پایههای مفهومی و اجرایی این معماری بهدرستی پیریزی شود. همانطور که در ساخت هر بنای پایداری، استحکام فونداسیون تعیینکنندهی دوام و کیفیت کل سازه است، در معماری داده نیز نادیده گرفتن پیشنیازها میتواند باعث ایجاد گلوگاههایی شود که در مراحل بعدی به سختی قابل جبران هستند.
معماری مدالیون در ظاهر از سه لایهی مشخص تشکیل شده، اما آنچه در نمودارهای رسمی دیده نمیشود و گاه بهسادگی از آن عبور میشود مجموعهای از تصمیمهای زیرساختی و فرآیندهای میانی است که عملاً ستون فقرات این معماری را شکل میدهند. تصمیمگیری دربارهی نحوهی ورود دادهها، انتخاب بین پردازش بلادرنگ یا دستهای، مدیریت دادههای خام، و انتخاب ابزارهای ETL و ارکستریشن، همگی در تعیین مسیر نهایی موفقیت نقش حیاتی دارند.
آنچه این تصمیمها را پیچیدهتر میکند، این است که اغلب آنها نه صرفاً فنی، بلکه تصمیمهایی هستند با ابعاد سازمانی و عملیاتی. برای مثال، انتخاب نادرست در نحوهی دریافت داده یا مدیریت دادههای خام میتواند بعدها در لایههای بالا منجر به پیچیدگی در مدلسازی، اختلال در تحلیل، یا حتی دوبارهکاریهای پرهزینه شود. از سوی دیگر، انتخاب درست در همین مراحل ابتدایی میتواند بنیانی برای معماریای مقیاسپذیر، منعطف و قابل اتکا فراهم کند.
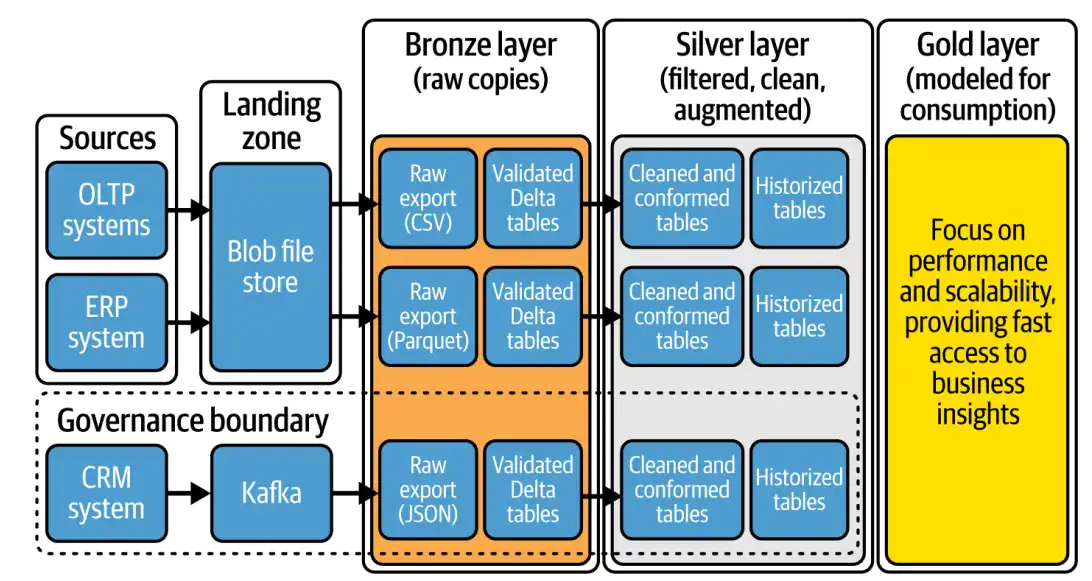
در این بخش، به دو عنصر کلیدی از این پیشنیازها میپردازیم که نقش آنها در معماری مدالیون بهویژه در فاز ورودی دادهها حیاتی است: Extra Landing Zones و Raw Data. این دو مفهوم، اگرچه ممکن است در ظاهر ساده بهنظر برسند، اما در عمل تعیین میکنند که داده با چه کیفیت، ساختار و اطمینانی وارد لایههای اصلی معماری شود.
ناحیهی فرود مازاد (Extra Landing Zone)
یکی از تصمیمهای مهم در طراحی ورودی دادهها به معماری مدالیون، تعیین مسیر ورود اطلاعات از سیستمهای منبع به لایهی Bronze است. در بسیاری از پیادهسازیهای ساده یا اولیه، این مسیر بهصورت مستقیم طراحی میشود: داده از منبع به Bronze میرسد. اما در پروژههای عملی و در مواجهه با پیچیدگیهای واقعی، یک مرحلهی واسط بهنام Extra Landing Zone بهعنوان ناحیهای مقدماتی و کنترلگر وارد بازی میشود. این ناحیه، در ظاهر بخشی از معماری مدالیون نیست و در نمودارهای رسمی نیز به آن اشارهای نمیشود، اما در عمل، در سناریوهایی که دادهها ناهمگون، فشرده، رمزنگاریشده یا ساختارنیافتهاند، Extra Landing Zone به ابزاری ضروری برای حفظ سلامت کل جریان تبدیل میشود.
در این لایهی میانی، دادهها پیش از ورود رسمی به لایه Bronze مورد بررسی، بازسازی یا کنترل کیفیت اولیه قرار میگیرند. وظایف این ناحیه، بسته به نوع منبع و حساسیت داده، میتواند شامل موارد زیر باشد:
- استخراج فایلها و تبدیل فرمتها: فایلهای فشرده یا با ساختارهای خاص مانند XML، JSON یا Avro ممکن است نیاز به استخراج، تبدیل یا مسطحسازی (flatten) داشته باشند.
- اعمال کنترلهای اولیه بر سازگاری: از جمله مقایسهی checksum، بررسی schema، یا تایید اعتبار ساختار دادهها.
- افزودن متادیتا: مانند تاریخ دریافت، منبع اصلی، یا تگگذاری امنیتی. رمزگشایی یا رمزنگاری اولیه: در مواردی که دادهها محرمانه هستند و نیاز به ورود امن به pipeline دارند.
Extra Landing Zone بهویژه در هنگام دریافت داده از منابعی مانند اپلیکیشنهای legacy، سرویسهای SaaS، یا سیستمهای عملیاتی غیرهمگن اهمیت پیدا میکند. در این موقعیتها، ورود مستقیم داده به لایهی Bronze میتواند باعث شکست ingestion، از دست رفتن داده، یا اختلال در مسیر تحلیلی شود.
از نظر مفهومی، شاید بتوان گفت که Extra Landing Zone مرز میان دنیای خارجی و دنیای داخلی معماری مدالیون است؛ جایی که دادهها پیش از ورود به ساختار لایهای و governed، برای نخستین بار تحت نظارت و پالایش اولیه قرار میگیرند. نادیده گرفتن این مرحله در طراحی، بهویژه در سازمانهایی با تنوع منابع داده، میتواند هزینههای سنگینی در سطوح بالاتر به همراه داشته باشد. در مقابل، استفادهی هوشمندانه از این ناحیه باعث افزایش مقاومت معماری در برابر ناپایداری منابع، تغییرات غیرمنتظره و ناسازگاریهای فرمی میشود و ورود دادهها به معماری مدالیون را امنتر، پایدارتر و کنترلشدهتر میکند.
دادههای خام (Raw Data)
در قلب لایهی Bronze، مفهومی بنیادین بهنام «دادهی خام» یا Raw Data قرار دارد؛ مفهومی که در نگاه اول ممکن است ساده بهنظر برسد، دادهای که مستقیماً و بدون تغییر از منبع به معماری وارد میشود. اما در عمل، این تعریف ساده جای خود را به مجموعهای از ملاحظات پیچیده، وابسته به نوع منبع، ساختار داده و محدودیتهای عملیاتی میدهد. برخلاف تصور رایج، دادهی خام الزاماً دادهای نیست که کاملاً دستنخورده باشد. در بسیاری از سناریوهای واقعی، پیش از آنکه داده وارد لایه Bronze شود، نیاز به عملیاتهایی بر روی آن وجود دارد که نه در حوزهی پاکسازی داده قرار میگیرند، نه در لایه Silver تعریف میشوند، اما برای ورود موفق داده به سیستم حیاتیاند. این عملیات گاه شامل:
- تبدیل فرمتها (مانند تبدیل XML به JSON یا پارس کردن فایلهای CSV فشرده)
- ساختاردهی مجدد (مثل مسطحسازی nested data یا بازآرایی کلید-مقدار)
- استخراج دادهها از سیستمهای اختصاصی یا non-standard
- اضافهکردن اطلاعات پایه مانند منبع، timestamp یا schema version
این فرایند نوعی میانجیگری دادهای (Data Mediation) یا پیشپردازش خفیف (Light Preprocessing) محسوب میشود که بدون تغییر در معنای دادهها، آنها را برای ورود قابل مدیریت به ساختار Medallion آماده میکند.
برای مثال، فرض کنید دادهای از یک سامانه بانکی پیچیده مانند T24 استخراج میشود. این داده ممکن است در قالب XMLهای بزرگ، با ساختاری تودرتو و شامل چندین سطح ارجاع متقابل ارائه شود. بدون اعمال حداقلی از تبدیل و مسطحسازی، امکان ذخیرهسازی مستقیم این داده در Bronze وجود ندارد؛ نه بهدلیل ضعف در زیرساخت، بلکه بهدلیل عدم آمادگی داده برای لایه های پایین دستی پردازش downstream processing.
از همین رو، در معماری مدالیون، Raw Data بهتر است نه بهعنوان “دادهی بدون تغییر”، بلکه بهعنوان “دادهی بدون تغییر معنایی” درک شود. این تمایز ظریف، اما حیاتی است. ممکن است عملیاتهایی روی داده انجام شود، اما تا زمانی که معنا، ساختار منطقی یا محتوای تحلیلی داده دستنخورده باقی بماند، داده هنوز خام محسوب میشود. نادیدهگرفتن این واقعیت میتواند منجر به طراحیهای اشتباه در pipelineها شود، برای مثال، فرض ورود مستقیم دادههای پیچیده و غیرقابل خواندن به لایه Bronze، که در عمل با شکست ingestion، پیچیدگی بیش از حد در downstream tasks، یا بروز خطاهای تحلیلی همراه خواهد بود.
در نتیجه، در طراحی معماری مدالیون، لازم است مفهوم Raw Data نه بهعنوان یک وضعیت باینری (خام/غیرخام)، بلکه بهعنوان یک طیف از آمادگی پردازشی در نظر گرفته شود. تنها در این صورت است که میتوان ابزار ingestion را هوشمندانه طراحی کرد، مدلسازی اولیه را واقعبینانه انجام داد، و لایه Bronze را بهدرستی بهعنوان سکوی پرتاب جریان داده سازمانی بنا نهاد.
معماری مدالیون
با گسترش معماریهای Lakehouse و رواج استفاده از Delta Lake، الگوی سهلایهای معماری مدالیون به یکی از ساختارهای پراستفاده در طراحی سیستمهای مدرن داده تبدیل شده است. اما در عمل، با وجود شهرت این مدل، درک درست و کاربردی از لایههای آن برای بسیاری از سازمانها آسان نیست. بسیاری از تیمها هنگام پیادهسازی این معماری، با ابهامات فراوانی درباره مرزهای عملکردی، نحوه تعامل بین لایهها، و بهترین شیوههای طراحی مواجه میشوند. بههمین دلیل، گرچه چارچوب مدالیون در نگاه اول ساده و منطقی بهنظر میرسد، اما در واقعیت، پیادهسازی آن بدون شناخت دقیق از عملکرد هر لایه میتواند منجر به طراحیهای پیچیده و غیرکارآمد شود.
در گام نخست، باید تأکید کرد که این لایهها ماهیتی منطقی (logical) دارند، نه الزاماً فیزیکی. بهعبارت دیگر، وقتی از لایه Bronze صحبت میکنیم، منظور یک مسیر مفهومی برای دستهای از دادههاست که ممکن است در لایههای فیزیکی گوناگونی ذخیره یا پردازش شوند. درک این موضوع کمک میکند تا با ذهنی بازتر به طراحی معماری داده بپردازیم و دامنهی هر لایه را بر اساس نیازهای پروژه مشخص کنیم.
در ادامهی هر یک از لایهها بهتفصیل مورد بررسی قرار میگیرند. ابتدا با Bronze آغاز میکنیم، جایی که دادهها بهصورت خام و بدون دستکاری ذخیره میشوند. سپس به لایه Silver میرسیم، جایی که دادهها پالایش شده، کیفیت آنها بهبود یافته و برای تحلیل آماده میشوند. در نهایت به لایه Gold میپردازیم، جایی که دادهها بهشکل بهینهشده و آماده برای تصمیمسازیهای کلان، ارائه میشوند. در هر بخش، هم به ویژگیهای مفهومی پرداخته میشود و هم به چالشها، تکنیکها و تجربههای عملی مرتبط.
لایهی برونز در معماری مدالیون
در معماری مدالیون، مسیر پالایش و ارزشآفرینی از دادهها با لایهی Bronze آغاز میشود، جایی که دادهها برای نخستینبار از منابع مختلف جمعآوری و بهصورت خام و بدون هیچگونه تغییر یا پردازشی ذخیره میشوند. این لایه نقش یک مخزن مرکزی (central repository) را ایفا میکند که نسخهای کامل و دستنخورده از دادهها را نگه میدارد؛ نسخهای که هم برای ارجاعهای بعدی در چرخهی پردازش و هم برای ممیزی (auditing)، اجرای مجدد پردازش دادهها از ابتدا (replay) یا حتی استخراج مجدد اطلاعات (re-extraction) کاربرد دارد. از همین رو، لایهی Bronze نهتنها نقطهی آغاز زنجیرهی پردازش محسوب میشود، بلکه مبنای تمامی لایههای بالادستی در تحلیل دادهها و تصمیمسازی کسبوکار نیز هست.
سلسه مراتب پردازش در لایهی برونز
یکی از سؤالات متداول در طراحی این لایه آن است که آیا باید آن را یک لایهی فیزیکی یکپارچه در نظر گرفت یا از چند زیرلایه (sub-layer) تشکیل داد. پاسخ به این پرسش بستگی زیادی به میزان پیچیدگی منابع داده، الزامات فنی سازمان، و الگوهای ورود داده دارد. در پروژههای ساده، دادهها میتوانند مستقیماً وارد لایهی Bronze شوند. اما در معماریهای پیچیدهتر، اغلب پیش از ورود به Bronze، از یک یا چند Landing Zone استفاده میشود، فضاهایی موقت که دادهها را بهصورت خام دریافت میکنند تا پس از آمادهسازی، به لایهی اصلی منتقل شوند.
ساختار پردازش در این لایه معمولاً بهصورت سلسلهمراتبی طراحی میشود که شامل مراحل زیر است:
- ذخیرهسازی موقت (Staging)
- پالایش اولیه داده
- تبدیل فرمت به ساختارهای بهینهشده مانند Delta Lake Format
در این مراحل اولیه، عملیاتی همچون بازکردن فایلهای فشردهشده، بررسی checksum برای اطمینان از صحت داده، ساخت metadata، و اعمال سیاستهایی نظیر رمزنگاری (encryption) یا طبقهبندی دادهها انجام میشود. این عملیات، بهخلاف تبدیلهای پیچیدهی داده، بیشتر به هدف حفظ یکپارچگی (Data Integrity) و مدیریتپذیری بهتر انجام میشوند، نه برای تغییر محتوای دادهها.
طراحی الگوی دریافت داده (Data Ingestion Patterns)
در ادامهی طراحی لایهی Bronze، انتخاب الگوی مناسب برای دریافت و ورود داده به سیستم، اهمیت بسیار بالایی دارد. چراکه هر منبع داده، شیوهی خاص خود را برای عرضهی اطلاعات دارد:
- برخی منابع خروجی کامل (Full Extract) از کل دادهها ارائه میدهند.
- برخی تنها تغییرات جدید (Incremental Load) را ارسال میکنند.
- و برخی نیز دادهها را بهصورت پیوسته و لحظهای (Real-Time Streaming) در اختیار میگذارند.
در نتیجه، لازم است که معماری Bronze از همان ابتدا بر اساس این تنوع در منابع و الگوها طراحی شود. انتخاب مناسب بین پردازش دستهای (Batch Processing)، افزایشی (Incremental) یا جریانمحور (Streaming)، در این مرحله تعیینکنندهی کیفیت، مقیاسپذیری و بهرهوری سیستم در مراحل بعدی خواهد بود.
الگوهای ورود داده
با توجه به تنوع منابع داده، انتخاب الگوی مناسب برای دریافت داده، گام بعدی مهم در طراحی لایه Bronze است. هر الگو مزایا و معایب خاص خود را دارد و متناسب با نیاز عملیاتی سازمان انتخاب میشود:
۱. Full Load: جامع، اما پرهزینه
در این روش، کل دادهها بهصورت کامل و در بازههای زمانی مشخص وارد Bronze میشوند. مزیت اصلی آن، کامل بودن و قابلیت بازپخش دادههاست، اما معایب آن در منابع مصرفی، ذخیرهسازی و زمان اجراست. در Full Load معمولاً این اقدامات انجام میشود:
- بررسی ساختار و صحت فایلها (Checksum)
- ایجاد متادیتا برای پیگیری و شفافسازی
- رمزنگاری یا حذف سطرهای نامعتبر، در صورت نیاز
- نگهداری نسخههای کامل و دستنخورده برای اهداف قانونی یا تحلیل تاریخی
۲. Incremental Load: هوشمند، مقیاسپذیر
لود افزایشی فقط دادههای جدید یا تغییریافته را وارد میکند. این روش، بهطور خاص برای محیطهای پویا و زنده مناسب است. دو سناریو اصلی در این الگو:
- Append Mode: درج صرف رکوردهای جدید، بدون تغییر رکوردهای قبلی (مناسب برای لاگها و رویدادها)
- Merge Mode (Upsert): درج و بروزرسانی رکوردها بر اساس کلید اصلی (مناسب برای دادههای متغیر مانند سفارشها یا موجودی انبار)
برای پیادهسازی مؤثر لود افزایشی، وجود یک ستون زمانی قابل اعتماد (مانند updated_at یا last_modified) در سیستم منبع ضروری است. این ستونها به سیستم اجازه میدهند تا بهدقت تشخیص دهد کدام رکوردها از زمان آخرین لود تغییر کردهاند. در صورتی که چنین ستونی در منبع وجود نداشته باشد، باید از ابزارهایی مانند Change Data Capture (CDC) بهره گرفت. CDC تغییرات درج، حذف و بهروزرسانی را با استفاده از تراکنش لاگهای پایگاهداده استخراج میکند و امکان بازسازی دقیق تغییرات را فراهم میسازد.
برای کنترل بهتر جریان داده، از تکنیکهای زیر میتوان بهره گرفت:
- استخراج دادهها از نقطهی مرجع مشخص (مثلاً با استفاده از max(updated_at) در لایهی Bronze)
- استفاده از Delta Transaction Log برای ردیابی تغییرات داخلی
- نگهداری یک جدول کنترل متادیتا (Metadata Control Table) برای ردیابی آخرین رکوردهای پردازششده و جلوگیری از تکرار لود
استفاده از لودهای افزایشی نهتنها زمان و منابع پردازشی را بهشدت کاهش میدهد، بلکه انسجام ساختاری لایههای بعدی (مثل Silver و Gold) را نیز حفظ میکند. در این معماری، هر لایه میتواند صرفاً دادههای تغییر یافته را دریافت و بهروزرسانی کند، بدون نیاز به بازپردازش کل مجموعه داده. این مدل هم از لحاظ کارایی (Performance) و هم از منظر انعطافپذیری معماری (Architectural Agility)، انتخابی هوشمندانه برای سازمانهایی است که با دادههای بزرگ و متغیر سروکار دارند.
دادههای تاریخی در لایهی برونز
در معماری مدالیون، لایهی Bronze نخستین نقطهی تماس دادهها با زیرساخت تحلیلی سازمان است؛ جایی که دادههای خام، دستنخورده و بدون پردازش از منابع گوناگون گردآوری و ذخیره میشوند. این لایه، مشابه با نقش staging area در معماریهای سنتی انبار داده (Data Warehouse)، بهعنوان یک مخزن امن و قابلاتکا برای دادههای ورودی عمل میکند. یکی از مهمترین اهداف لایهی Bronze، ایجاد آرشیوی تاریخی از دادهها است، آرشیوی که نهتنها امکان تحلیل گذشتهنگر (Retrospective Analysis) و ردیابی تغییرات را فراهم میآورد، بلکه در مواقع ضروری میتواند منبعی برای بازیابی دادهها و اجرای مجدد فرآیندهای تحلیلی باشد.
در مواقعی که دادهها بهصورت لود کامل (Full Extract) از سیستم منبع استخراج میشوند، لایهی Bronze بهترین محل برای نگهداری نسخههای مختلف این دادهها در گذر زمان است. معمولاً این دادهها در قالبهایی مانند Parquet یا Delta Lake ذخیره میشوند که برای حجم بالا و خواندن سریع بهینه هستند. برای سازماندهی بهتر این فایلها، از ساختارهای پوشهبندی شده بر اساس تاریخ استفاده میشود. بهعنوان نمونه، هر لود ممکن است در پوشهای ذخیره شود که با قالب YYYY/MM/DD نامگذاری شده است—مثلاً 2025/08/27 برای لودی که در ۲۷ آگوست ۲۰۲۵ انجام شده است. این ساختار پوشهای باعث میشود:
- دسترسی به نسخههای قدیمی سادهتر باشد؛
- وضعیت گذشتهی سیستم با دقت بازسازی شود؛
- امکان مقایسهی تغییرات بین لودهای متوالی فراهم گردد.
در این لایه، منظور از ثبت تاریخی (Historization) صرفاً ثبت نسخههای مختلف دادهها در زمانهای گوناگون است، نه پیادهسازی الگوهایی مانند SCD Type 2 که در لایههای تحلیلیتر مثل Silver و Gold رایج هستند. دادههای ذخیرهشده در لایهی Bronze عمدتاً بهعنوان Immutable Data در نظر گرفته میشوند؛ یعنی دادههایی که پس از ذخیره شدن، دیگر ویرایش یا حذف نمیشوند و فقط امکان افزودن دادههای جدید یا ترکیب با دادههای قبلی وجود دارد. این ویژگی باعث میشود که این لایه نقش کلیدی در حفظ پایداری، قابلیت ردگیری (Traceability) و شفافیت کل فرآیندهای پردازش داده ایفا کند. برای مثال، اگر در مراحل بعدی (در لایههای Silver یا Gold) با مشکلی در کیفیت داده، خطای پردازشی یا تصمیمگیری اشتباه روبرو شوید، میتوانید با مراجعه به نسخهی دستنخوردهای از داده در Bronze، پردازش را از نقطهای مشخص مجدداً آغاز کنید، بدون اینکه نیاز به استخراج مجدد از سیستم منبع باشد.
با وجود مزایای بسیار، نگهداری دادههای تاریخی در لایهی Bronze خالی از چالش نیست. یکی از مهمترین این چالشها، تغییر ساختار دادهها (Schema Evolution) در طول زمان است. در مسیر رشد سازمان یا تغییر در سیستمهای مبدأ، ممکن است:
- ستونهای جدید به دادهها افزوده شوند؛
- نام یا نوع دادههای موجود تغییر کند؛
- فرمت دادهها بین لودهای مختلف دچار تغییر شود.
اگر این تغییرات بهدرستی مدیریت نشوند، سازگاری (Compatibility) و یکپارچگی (Integrity) دادهها به خطر خواهد افتاد، بهویژه هنگام بازخوانی دادههای قدیمی یا تجمیع آنها با دادههای جدید. مدیریت مؤثر Schema Evolution موضوع مهمی است که باید بهصورت اصولی در لایهی Bronze پیادهسازی شود؛ چرا که این لایه، شالودهی همهی لایههای تحلیلی بعدی محسوب میشود. در ادامهی مقاله، بهطور ویژه به استراتژیهای مدیریت تغییر ساختار داده نیز خواهیم پرداخت.
تکامل و مدیریت اسکیمای داده در لایهی برونز
در معماری مدالیون، لایهی Bronze نخستین نقطهی ورود دادهها به سامانه است. در این لایه، دادهها معمولاً بهصورت خام و بدون اعمال ساختار مشخصی ذخیره میشوند. اما همین مرحلهی ابتدایی، یکی از چالشبرانگیزترین جنبهها را در دل خود دارد: تغییر ساختار دادهها در طول زمان یا همان Schema Evolution. در محیطهایی که با منابع دادهی متنوع و پویایی سر و کار دارند، مثلاً سازمانهایی با چندین تیم یا سیستم منبع، تغییرات اسکیمایی کاملاً اجتنابناپذیرند. از همین رو، چگونگی مواجهه با این تغییرات، تأثیر مستقیمی بر عملکرد لایههای بعدی در معماری دارد.
دو رویکرد کلیدی: schema-on-read و schema-on-write
در برخورد با اسکیمای داده، سازمانها معمولاً یکی از دو رویکرد زیر را اتخاذ میکنند—یا ترکیبی از هر دو:
۱. schema-on-read در این روش، دادهها بدون اعمال اسکیمای صریح، ذخیره میشوند و فقط هنگام خواندن تفسیر میشوند. ساختار داده یا inferred میشود (یعنی بهصورت خودکار تشخیص داده میشود) یا توسط کاربر در زمان خواندن اعمال میشود. این رویکرد بهدلیل انعطاف بالا، برای دادههای نیمهساختیافته مانند JSON، CSV، Parquet و دادههایی که ساختار مشخصی ندارند بسیار مناسب است.
برای مثال، فرض کنید دادههای روزانه از سیستمهای مختلف، بهصورت فایلهایی ذخیره شوند که در مسیرهایی مانند bronze/events/2025/08/27/ قرار گرفتهاند (فرمت YYYY/MM/DD). با استفاده از schema-on-read، میتوان این دادهها را بدون نیاز به تعریف اسکیمای قبلی خواند، تحلیل کرد یا به مراحل بعدی فرستاد. این ویژگی، امکان پردازش آسان مجموعه دادههایی با ساختار متغیر را فراهم میآورد.
۲. schema-on-write در این رویکرد، اسکیمای داده—شامل نام ستونها، نوع دادهها، کلیدها و سایر جزئیات—پیش از ذخیرهسازی مشخص میشود. سیستم بررسی میکند که داده، با ساختار مورد انتظار سازگار باشد، و در غیر این صورت خطا برمیگرداند. این رویکرد، گرچه سختگیرانهتر است، اما برای دادههای ساختیافته و قابل اعتماد مناسبتر است. در Apache Spark، ساختار دادهها بهصورت StructType تعریف میشود که نشان میدهد هر ستون چه نوع دادهای دارد. اگر هنگام ذخیره داده در فرمت Delta Lake اسکیمایی بهصورت صریح تعریف نشده باشد، سیستم آن را بهصورت خودکار از DataFrame ورودی استخراج میکند.
در عمل، بسیاری از معماریهای مدرن بهویژه در لایهی Bronze، از ترکیبی از schema-on-read و schema-on-write استفاده میکنند:
- در مرحلهی ورود اولیه (Landing Zone یا pre-Bronze)، از schema-on-read استفاده میشود. دادهها بهسادگی ذخیره میشوند بدون آنکه ساختار خاصی تحمیل شود.
- در گام بعد، زمانی که دادهها به یک ساختار قابل کوئری (queryable) تبدیل میشوند، مثلاً تبدیل به فرمت Delta، رویکرد schema-on-write اعمال میشود تا اسکیمای مشخص و استاندارد اعمال گردد.
در نهایت، لایهی Bronze با پذیرش تغییرات ساختاری در دادهها و فراهم کردن یک پایهی محکم برای مراحل بعدی، نقشی کلیدی در موفقیت کل معماری مدالیون ایفا میکند، مشروط بر آنکه تغییرات اسکیمایی با دقت، ابزار مناسب و در زمان درست مدیریت شوند.
بررسیهای فنی اعتبار دادهها در لایه برونز
در معماری مدالیون، لایهی Bronze اولین نقطهی تماس با دادههای خام است و نقشی کلیدی در تضمین کیفیت و انسجام دادهها ایفا میکند. برخلاف تصور رایج، این لایه فقط یک محل ذخیرهسازی ساده نیست، بلکه بهعنوان نخستین ایستگاه دفاعی در برابر دادههای ناقص، ناسالم یا ناهمساز عمل میکند. با توجه به اینکه دادههای ورودی از منابع مختلف با فرمتهای متنوعی مانند JSON، XML یا CSV ارسال میشوند، احتمال ورود خطا یا ناسازگاری ساختاری بسیار بالاست. در چنین شرایطی، اجرای کنترلهای فنی در همین نقطه برای جلوگیری از سرایت خطا به لایههای Silver و Gold حیاتی است.
هدف از اعتبارسنجی در این مرحله، اطمینان از صحت فنی دادهها، کنترل اسکیمای ورودی، و مستندسازی وضعیت دادههاست. این کنترلها بهویژه در معماریهایی که از رویکرد schema-on-write استفاده میکنند اهمیت دوچندان دارند، زیرا در صورت عدم تطابق اسکیمای ورودی با جدول مقصد، عملیات نوشتن متوقف میشود. از جمله رایجترین کنترلها میتوان به موارد زیر اشاره کرد:
- بررسی قالب فایل (Format Check)
- بررسی اسکیمای داده (Schema Validation)
- بررسی کامل بودن ستونهای الزامی
- شناسایی تغییرات ناخواسته در اسکیمای منبع (Schema Drift)
- شناسایی خطاهای آشکار مانند فیلدهای null یا نوع داده نادرست
نوع اجرای این کنترلها وابسته به سیاستهای سازمان است. برخی سازمانها رویکرد سختگیرانه (intrusive) اتخاذ میکنند و در صورت مشاهده خطا، جریان داده را متوقف کرده و دادهی معیوب را قرنطینه میکنند. برخی دیگر، با رویکرد منعطفتر (non-intrusive)، دادهی معیوب را همراه سایر دادهها ذخیره کرده و اعتبارسنجی را به مراحل بعدی واگذار میکنند. انتخاب میان این دو بستگی به حساسیت تحلیلی، نوع مصرفکنندگان داده و میزان تحمل سازمان در برابر خطا دارد.
اجرای این کنترلها معمولاً بهکمک ابزارهایی مانند ویژگیهای داخلی Delta Lake (نظیر schema enforcement و mergeSchema) و فریمورکهایی مانند Great Expectations، Delta Live Tables یا dbt انجام میشود. این ابزارها قابلیتهایی برای تعریف قوانین اعتبارسنجی، بررسی مقادیر گمشده، و مانیتورینگ پیوسته ارائه میدهند. همچنین پلتفرمهایی مانند Monte Carlo Data یا Ataccama امکان هشداردهی و تحلیل کیفیت را بهصورت هوشمند فراهم میکنند. در بسترهای ارکستراسیون مانند Airflow یا Azure Data Factory، میتوان کنترلهای کیفیت را بهعنوان بخشی یکپارچه از pipeline پیادهسازی کرد.
در موارد خاص، طراحی راهکارهای سفارشی با استفاده از اسکریپتهای Python یا SQL و یک مخزن متمرکز متادیتا میتواند انتخاب بهتری باشد، بهویژه در زیرساختهای پیچیده یا ناهمگون. برخی ابزارها مانند Azure Data Factory از قابلیت schema drift detection نیز پشتیبانی میکنند که در مواجهه با تغییرات ناخواستهی ساختار داده بسیار مفید است.
در نهایت، اجرای مؤثر اعتبارسنجی داده مستلزم همکاری نزدیک میان تیمهای مختلف، از تیمهای منبع و توسعهدهندگان پلتفرم گرفته تا مهندسان داده و تحلیلگران کسبوکار، است. فرآیند شناسایی و اصلاح خطا باید بهطور شفاف تعریف شود و تیمهای مالک داده مسئولیتپذیری کامل در قبال دادههای خود داشته باشند. بهطور کلی، لایهی Bronze تنها نقطهی ورود داده نیست، بلکه خط مقدم دفاعی در برابر بینظمیهای ساختاری و کیفیت پایین است. کنترلهای فنی مستقر در این لایه نقش مهمی در جلوگیری از انتشار خطا به مراحل بعدی دارند و زیرساختی مطمئن برای تحلیلپذیری و اعتماد در لایههای Silver و Gold ایجاد میکنند.
استفادهپذیری و حاکمیت داده در لایه Bronze: توازن میان انعطاف و کنترل
لایهی Bronze در معماری مدالیون، نقطهی شروع جریان دادههاست و مسئول گردآوری دادههای خام از منابع گوناگون است. با این حال، استفادهی مستقیم از دادههای این لایه برای کاربران کسبوکار، گرچه ممکن است جذاب به نظر برسد، در عمل با چالشهای جدی مواجه است. ساختار پیچیدهی دادهها، فرمتهای متنوع، و وابستگی عمیق به منطق سیستمهای منبع باعث میشود تفسیر صحیح این دادهها تنها با درک فنی بالا امکانپذیر باشد. در نتیجه، استفادهی تحلیلی مستقیم از Bronze، بهویژه برای کاربران غیرفنی، هم دشوار و هم پرریسک است.
از منظر حاکمیت داده، لایه Bronze نیازمند کنترلهای دقیق و سیاستهای سختگیرانهتری است. دسترسی به این دادهها باید محدود و مبتنی بر نقش (RBAC) باشد تا از تغییرات ناخواسته، حذفهای تصادفی یا نشت اطلاعات جلوگیری شود. همچنین، یکی از اصول بنیادین این لایه، تغییرناپذیری است (immutable): پس از بارگذاری، دادهها نباید تغییر کنند. این اصل، امکان بازتولید، ردیابی، و تحلیل تاریخی را تضمین میکند. البته در شرایط خاص، مثل افزودن متادیتا یا فیلتر اطلاعات حساس، میتوان استثنا قائل شد، مشروط بر آنکه شفافیت، مستندسازی و قابلیت پیگیری بهطور کامل رعایت شود.
برای پشتیبانی از این اصول، یک سامانهی ثبت وقایع (logging) ضروری است. این سیستم باید اطلاعاتی نظیر منبع داده، فرمت، زمان دریافت، و وضعیت پردازش اولیه را مستند کند. همچنین، تعریف هشدارهایی برای شناسایی ناهنجاریها، مانند تفاوت حجم یا تأخیر در دریافت دادهها، بخشی حیاتی از راهکارهای پایش و پیشگیری بهشمار میآید. در کنار این موارد، پیادهسازی یک برنامه پاسخگویی به خطا (Incident Response Plan)، مستندسازی کامل تغییرات، کاتالوگسازی دادهها، و اجرای فرآیندهای بازبینی مستمر، همگی لازمهی مدیریت پایدار و حرفهای این لایهاند.
در نهایت، لایه Bronze نهتنها محل نگهداری دادههای خام، بلکه ستون فقرات انعطافپذیری در معماری مدرن Lakehouse است. دادهها در این لایه معمولاً بدون تغییر باقی میمانند، اما در صورت نیاز به انطباق با الزامات امنیتی یا سازگاری ساختاری، ممکن است بهصورت کنترلشده، غنیسازی یا پیشپردازش سبک شوند. در هر دو حالت، موفقیت این لایه در گرو رعایت دقیق اصول حاکمیت داده و حفظ تعادل میان انعطاف عملیاتی و کنترل ساختاری است.
لایهی برونز در عمل
لایه Bronze در معماری مدالیون نه صرفاً یک بخش ذخیرهسازی، بلکه بنیانی محکم و حیاتی برای کل چرخهی پردازش داده است. این لایه وظیفه دارد دادهها را به اصیلترین شکل ممکن، درست به همان صورتی که از سیستمهای منبع دریافت شدهاند، ثبت و نگهداری کند. در واقع، Bronze نقطهای است که در آن دادهها، بدون هیچگونه تغییر، غنیسازی یا حذف، بهصورت کامل و پایدار وارد معماری داده میشوند؛ گویی عکس فوریای از واقعیت کسبوکار در آن لحظه گرفته میشود.
این اصالت و تغییرناپذیری داده در لایه Bronze، نهتنها به حفاظت در برابر از دست رفتن داده یا خرابی دادهها (corruption) کمک میکند، بلکه قابلیت بازیابی کامل و بازاجرای پایپلاینها را نیز فراهم میسازد. از این جهت، میتوان Bronze را بهعنوان لایهای دانست که نوعی «بیمه داده» برای معماری کلی دریاچهداده فراهم میکند، لایهای که اگر تمام پردازشهای بعدی به هر دلیل با مشکل مواجه شوند، همچنان میتوان به آن بازگشت کرد و از ابتدا، فرآیند را بازسازی نمود.
با این حال، باید توجه داشت که لایه Bronze یک ساختار ایستا یا صلب نیست. طراحی این لایه باید متناسب با نیازهای خاص سازمان، ویژگیهای دادههای منبع، و محدودیتهای عملیاتی شکل گیرد. در برخی سناریوها، ممکن است لازم باشدlanding zones های مجزا برای انواع مختلف داده—مثلاً دادههای تراکنشی، لاگ، یا دادههای batched—ایجاد شود. در برخی موارد نیز تعریف یک لایه پیشپردازش موقت (staging or preprocessing zone) ضروری است تا دادهها ابتدا پاکسازی جزئی، اعتبارسنجی اولیه یا افزایش داده (enrichment) را تجربه کنند، پیش از آنکه به صورت رسمی وارد Bronze شوند.
از سوی دیگر، برخی سازمانها بهجای ذخیرهسازی فیزیکی تمام دادهها در این لایه، از مدلهای منطقی یا مجازیسازی (virtual Bronze) بهره میبرند. در این روش، دادهها همچنان در سیستمهای منبع باقی میمانند، اما از طریق abstraction یا تعریف نماها (views)، ساختاری نمایشی از آنها برای مصرف در معماری مدالیون ایجاد میشود. این رویکرد بهویژه زمانی مفید است که دادهها حجم بالایی دارند، تغییرپذیر هستند، یا نیاز به ذخیرهسازی فیزیکی در مراحل اولیه احساس نمیشود. به این ترتیب، میتوان از مزایای دسترسی به دادهی خام بهرهبرد و در عین حال، بار ذخیرهسازی و هزینههای مرتبط را کاهش داد.
با وجود نقش زیربنایی لایه Bronze در حفظ یکپارچگی و اصالت تاریخی دادهها، نمیتوان آن را برای اهداف تحلیلی مستقیم مناسب دانست. دادههای موجود در این لایه اغلب با تکرارها، ناسازگاریها، مقادیر گمشده یا ساختارهای ناهماهنگ همراه هستند، ویژگیهایی که بهجای بینش دادن به تحلیلگران، آنها را با خطا و ابهام مواجه میکند. به همین دلیل، گذار از Bronze به Silver، نه تنها یک توصیه، بلکه یک ضرورت عملی در معماری داده محسوب میشود. در Silver، دادهها پالایش میشوند، ساختار میگیرند، با منابع دیگر تلفیق میشوند، و در قالبی تحلیلپذیر و معنادار ارائه میگردند. اما این گذار، تنها در صورتی موفق خواهد بود که طراحی لایه Bronze بهدرستی و با آگاهی از نیازهای آینده انجام شده باشد.
بنابراین، میتوان گفت که لایه Bronze، هرچند غالباً کمتر مورد توجه کاربران نهایی قرار میگیرد، یکی از استراتژیکترین لایههای معماری مدالیون است. لایهای که اگر بهدرستی طراحی، پیادهسازی، و مدیریت شود، کل زیرساخت دادهای سازمان را در برابر تغییر، خطا، و عدم قطعیت مقاوم میسازد.
لایه Bronze در معماری مدالیون نقش سنگبنای پایپلاین داده را بازی میکند؛ جایی که همهچیز از آن آغاز میشود. اما باید توجه داشت که طراحی این لایه نباید تنها بر مبنای ساختارهای از پیش تعیینشده باشد، بلکه باید بر اساس نیازهای عملیاتی، پیچیدگیهای منبع، و الزامات حاکمیتی بهصورت منعطف و هدفمحور طراحی شود. هرچند دادههای خام ارزش تاریخی و یکپارچگی اطلاعات را تضمین میکنند، اما فقط با عبور از لایهی Silver است که دادهها میتوانند به شکل آماده برای تحلیلهای تجاری و تصمیمگیریهای راهبردی تبدیل شوند.
لایهی سیلور در معماری مدالیون
در معماری دادهی مدرن، لایه Silver نخستین مرحلهی واقعی برای معنابخشی به دادههاست. اگر لایهی Bronze بهعنوان دریچهی ورود دادههای خام و ثبتشده از منابع متنوع عمل میکند، لایهی Silver همان نقطهای است که در آن دادهها از حالت صرفاً ذخیرهشده خارج شده و به سمت مصرف تحلیلی، عملیاتی، و تصمیممحور حرکت میکنند. دادههایی که اکنون در وضعیت قابل کوئری قرار دارند، یعنی میتوان آنها را از طریق ابزارهای تحلیل یا پایگاههای پردازشی فراخوانی کرد، هنوز ممکن است مشکلاتی مانند تکرار، ناهماهنگی ساختاری، یا کیفیت پایین داشته باشند. بنابراین، ورود به Silver بهمعنای ورود به فرایند پالایش عمیق دادهاست.
در این لایه، تمرکز بر روی ارتقاء کیفیت و معنادار ساختن دادههاست. بسیاری از عملیات ضروری در این مرحله انجام میگیرند: قالببندی ناهماهنگ تاریخها و زمانها اصلاح (datetime format standardization) میشود، دادههای مرجع با استانداردهای مرجع معتبر تطبیق (reference data enforcement) مییابند، نامگذاری ستونها و فیلدها بر اساس اصول یکپارچهسازی میشود، دادههای تکراری حذف میگردند، و ردیفهایی که کیفیت پایینی دارند یا با هدف تحلیل همراستا نیستند، کنار گذاشته میشوند. این مرحله، نقطهای است که دادهها را از وضعیت صرفاً در دسترس بودن به وضعیت قابل استفاده بودن ارتقاء میدهد.
با این حال، نباید تصور کرد که در این مرحله دادهها بهصورت نهایی تجمیع یا یکپارچه شدهاند. برعکس، در بسیاری از طراحیها، دادههای Silver هنوز به صورت تفکیکشده بر اساس منبع نگهداری میشوند و عملیات همگرایی، تجمیع بین سیستمی (cross-system merging) یا مدلسازی تحلیلی پیچیده به مرحلهی بعد، یعنی لایهی Gold، واگذار میشود. لایهی Silver را میتوان به مثابه مرحلهی پاکسازی و تصفیه در کارخانهای دانست که مواد خام را برای فرآوری نهایی آماده میسازد؛ جایی که دادهها، پیش از ورود به کاربردهای واقعی، از هر گونه آلودگی، تکرار، و ناهماهنگی زدوده میشوند.
از منظر معماری، طراحی این لایه هم (مانند Bronze) نیازمند تصمیمگیریهای ظریف، بهویژه در مواجهه با تنوع ساختار منابع، استانداردهای دامنههای کسبوکار، و نیازهای متفاوت تیمهای تحلیلگر و محصولمحور است. در ادامه، باید به دقت بررسی کرد که چه دادهای ارزش پاکسازی دارد، چه دادهای باید حذف شود، و چه دادهای با چه سطح از غنیسازی وارد مرحلهی بعد گردد.
لایهی Silver، پلی است بین دنیای دادههای ثبتشده و دنیای بینش و تحلیل. اگر بهدرستی طراحی و اجرا شود، میتواند کیفیت و یکپارچگی را تضمین کرده و زیرساختی پایدار برای تحلیلهای هوشمند و تصمیمگیریهای دقیق فراهم سازد. اما این فقط آغاز مسیر است، در ادامه، باید به طراحی مدلهای داده در این لایه، نحوهی مواجهه با تغییرات ساختاری، و نقش آن در پشتیبانی از سیستمهای عملیاتی و الگوریتمهای یادگیری ماشین پرداخت.
پاکسازی داده
در بسیاری از سازمانها، دادههایی که از سیستمهای عملیاتی به پلتفرم داده منتقل میشوند، از همان ابتدا با مشکلات کیفی همراه هستند. این مشکلات ممکن است ناشی از خطای انسانی، طراحی ضعیف سیستمهای منبع، یا ناهماهنگی میان سامانههای مختلف باشند. بنابراین، فرآیند پاکسازی باید با دقت، در چند مرحله، و بهصورت تکرارشونده طراحی شود.
بخشی از عملیات پاکسازی را میتوان بهطور خودکار در فاز ETL یا ELT انجام داد، اما در برخی موارد، بهترین راهکار اصلاح داده در همان منبع تولید آن است (Upstream Source). چرا که آن داده ممکن است نهفقط در پلتفرم تحلیلی، بلکه در سایر سیستمهای عملیاتی نیز کاربرد داشته باشد. در نتیجه، اصلاح مشکل در منبع، از انتشار خطا در سایر سیستمها جلوگیری میکند.
فرآیند پاکسازی میتواند مبتنی بر قوانین ETL صریح یا در برخی موارد از طریق جدولهای نگاشت (Mapping Tables) انجام شود. اما توسعه چنین فرآیندی پیچیده است و معمولاً به بازنگریهای چندمرحلهای نیاز دارد.
در ادامه برخی از فعالیتهای متداول در پاکسازی داده در لایه Silver آمده است:
- کاهش نویز و حذف دادههای نامعتبر: حذف ستونها یا ردیفهای غیرضروری، یا دادههایی که بازتابدهندهی منبع اصلی معتبر (golden source) نیستند.
- مدیریت Missing Values: حذف، جایگزینی با مقدار پیشفرض، یا استفاده از روشهای برآورد هوشمند (Imputation) بر اساس دادههای مجاور.
- حذف رکوردهای تکراری (Duplicate Removal): وجود داده تکراری مجاز است مگر اینکه نگهداشت آنها برای اهداف قانونی (مانند سناریوهای retention) ضروری باشد.
- حذف فاصلههای اضافی (Trimming Spaces): بهویژه در دادههای متنی، که فاصلههای پیشوندی یا پسوندی میتوانند روی جستوجو، مرتبسازی یا مقایسه اثر بگذارند.
- اصلاح خطاهای تایپی و قالبی (Error Correction): شامل تایپهای اشتباه، بزرگنویسی/کوچکنویسی ناهماهنگ، یا اشتباه در واحدهای اندازهگیری.
- شناسایی و اصلاح دادههای پرت (Outlier Correction): شناسایی مقادیر غیرعادی مثل جهش ناگهانی فروش که میتواند نشانگر مشکل کیفی باشد.
- بررسی سازگاری مفهومی (Consistency Checks): یکسانسازی اصطلاحات، اختصارات، و واحدهای اندازهگیری—مثلاً استفاده مداوم از “NL” بهجای ترکیب آن با “NETHERLANDS”.
- استانداردسازی قالبها (Format Standardization): مانند هماهنگسازی فرمت تاریخها بهصورت YYYY-MM-DD، حتی با وجود ترجیحات محلی متنوع.
- اصلاح نوع دادهها (Type Correction): اطمینان از اینکه ستونها نوع مناسبی دارند—عدد، تاریخ، عدد اعشاری و غیره.
- محدودسازی مقادیر (Range Validation): بررسی اینکه مقادیر موجود در ستونها در محدودههای منطقی و مورد انتظار قرار دارند.
- اعمال محدودیتهای یکتا و رابطهای (Uniqueness & Foreign Key Constraints): اطمینان از وجود روابط معتبر میان جداول و جلوگیری از رکوردهای یتیم (orphan).
- پنهانسازی دادههای حساس (Masking PII): حذف یا رمزنگاری اطلاعات شخصی (مثل کد ملی یا ایمیل) برای حفظ حریم خصوصی و رعایت مقررات.
- تشخیص دادههای غیرعادی (Anomaly Detection): شناسایی جهشها یا الگوهای غیرمنتظره که ممکن است نشانگر دادهی معیوب باشند.
- مدیریت دادههای مرجع (Master Data Management): اطمینان از دقت و یکنواختی دادههای حیاتی مشترک مانند کشورها، مناطق، کدها و …
- همریختسازی دادهها (Conforming to Common Data Models): همسانسازی ساختار دادهها با مدلهای داده مرجع یا مشترک در سطح سازمان.
این فهرست کامل نیست، اما بهخوبی نشان میدهد که پاکسازی داده تنها یک وظیفه فنی نیست. برای تدوین قوانین مؤثر پاکسازی، باید درک عمیقی از دادهها، منبع تولید آنها، و فرآیندهای مرتبط با کسبوکار داشته باشید.
دادههای نادرست را چه باید کرد؟
نکته مهم این است که دادههای نادرست یا رد شده معمولاً حذف نمیشوند. در عوض، این دادهها یا نشانهگذاری (Flag) میشوند یا از جریان اصلی داده فیلتر شده و در یک جدول یا فضای ذخیرهسازی مجزا با نامی مانند quarantine table نگهداری میشوند. این راهکار هم ردیابیپذیری (traceability) داده را حفظ میکند و هم از ورود دادههای بیکیفیت به مراحل بالاتر مانند Gold جلوگیری میکند.
حتی با بهترین قوانین پاکسازی، ممکن است در مرحلهی بعدی مانند تحلیل نهایی، ساخت مدلهای یادگیری ماشین، یا ساخت داشبورد مدیریتی، با مشکلات دادهای مواجه شوید. در این صورت، نیاز است که به عقب برگردید، ابتدا به لایه Silver و در برخی موارد حتی به لایه Bronze تا مشکل را از ریشه حل کنید. به همین دلیل، طراحی لایه Silver باید:
- قابل بازبینی (revisitable)
- قابل ردیابی (traceable) و
- منعطف (flexible) باشد.
در نهایت، لایه Silver همانجایی است که دادهها برای اولینبار به شکل انسانیتر، قابل درکتر، و قابل استفادهتری درمیآیند، برای تحلیلگر، مدلساز، یا سیستمهای گزارشدهی. و اکنون که دادهها پاکسازی شدهاند، پرسش مهم این است:
آیا دادهها باید با همان ساختار اصلی باقی بمانند؟ یا باید بازطراحی (remodel) شوند تا برای تحلیل بهتر، آمادهتر شوند؟
طراحی مدل داده در لایه Silver
پس از آنکه دادهها در لایه Bronze جمعآوری و ذخیره شدند، لایه Silver نخستین جاییست که دادهها از حالت صرفاً خام خارج شده و به شکل ساختاریافته، معنادار و قابلاستفاده درمیآیند. این لایه، مرز میان «ذخیرهسازی منفعل» و «مصرف هدفمند» داده است، چه برای تحلیل، چه برای ساخت مدلهای یادگیری ماشین، و چه برای گزارشسازی و ارائه از طریق API. مدلسازی داده در لایه Silver، فقط یک تصمیم فنی نیست؛ بلکه نیازمند بینشی عمیق نسبت به نیازهای تحلیلی، ویژگیهای منبع داده، محدودیتهای زیرساخت، و چشمانداز استراتژیک سازمان در حوزه مدیریت داده است. در ادامه، گامبهگام اجزای مهم طراحی مدل در این لایه را بررسی میکنیم:
همراستاسازی و تغییر نام ستونها
یکی از ابتداییترین و مؤثرترین اقدامات در لایه Silver، همراستاسازی نامها و ساختار ستونهاست. این کار ممکن است ساده به نظر برسد، اما تأثیر بالایی در کیفیت تحلیل، خوانایی مدل و همکاری تیمی دارد.
دلایل اهمیت این گام:
- نامگذاریهای استاندارد و توصیفی، درک داده را برای تحلیلگران و توسعهدهندگان آسانتر میکند.
- کاهش سردرگمی، خطا و تفسیر نادرست در کوئرینویسی و مدلسازی.
- همراستاسازی جداول از منابع مختلف برای تطبیق آسانتر در لایههای بعدی.
به عنوان مثال میتوان custID را به CustomerID یا ترکیب f_name و l_name را به FullName تغییر داد که نهتنها معنادارتر است، بلکه مصرفپذیری داده را افزایش میدهد.
همچنین انتخاب نوع دادهی (data type) صحیح نیز اهمیت بالایی دارد. استفاده از نوع داده اشتباه ممکن است منجر به تبدیلهای پنهان (implicit casting) در زمان اجرا شود، که میتواند باعث:
- کاهش سرعت کوئریها
- افزایش مصرف منابع محاسباتی
- بروز خطاهای تحلیلی شود.
میتوان از کوچکترین نوع دادهی متناسب با نیاز خود استفاده کنید تا هم عملکرد بهبود یابد و هم در مصرف فضای ذخیرهسازی صرفهجویی شود.
غیرنرمالسازی ساختارها
بر خلاف سیستمهای عملیاتی (OLTP) که در آنها نرمالسازی بهمنظور جلوگیری از افزونگی و حفظ سازگاری ضروریست، در لایه Silver تحلیلمحور بودن اولویت دارد. به همین دلیل، در این لایه معمولاً به سمت غیرنرمالسازی (Denormalized) حرکت میکنیم.
مزایای غیرنرمالسازی در Silver:
- سادهسازی ساختار دادهها برای مصرف سریعتر
- کاهش نیاز به JOINهای سنگین و پیچیده
- بهینهسازی عملکرد در سیستمهای ستونی مانند Parquet و Delta
به عنوان مثال: یک جدول غیرنرمالشدهی مشتری میتواند شامل اطلاعات شخصی، منطقه، سابقه خرید و سابقه ورود نیز باشد، همه در یک جدول، بدون نیاز به JOIN.. البته غیرنرمالسازی با افزایش حجم داده (به دلیل تکرار) همراه است. برای کنترل این موضوع، باید از وظایف بهینهسازی دورهای برای نگهداری جداول استفاده کرد.
پیادهسازی (Slowly Changing Dimensions) SCD Type 2
در تحلیلهای زمانی و مدلهای یادگیری ماشین، مهم است بدانیم چه چیزی، چه زمانی، و چگونه تغییر کرده است. ابعاد SCD نوع 2 این امکان را میدهند تا تاریخچه تغییرات دادهها را نگهداریم. ویژگیهای رایج SCD2:
- ستونهایی مانند start_date, end_date, is_current
- امکان تشخیص وضعیت فعلی و سابق موجودیتها
- پیادهسازی با استفاده از کلیدهای کسبوکاری یا هش
مثال: برای مشتریای که محل اقامتش از “شیراز” به “تهران” تغییر کرده، رکورد جدیدی با زمانبندی دقیق وارد میشود بدون حذف رکورد قبلی.
ساخت SCD2 در Silver اگرچه سنگین است، اما در مواردی که تاریخچه باید نزدیک به منبع بماند (مثلاً برای تطبیق با لاگها یا دادههای NoSQL)، ضروری است.
نگهداری SCD2 در Silver لایه میتواند بار سیستم را بالا ببرد و پیچیدگی ETL را افزایش دهد، اما برای سازمانهایی که تاریخچهی دقیق داده برایشان اهمیت دارد یک مزیت بزرگ است. بسیاری از تیمها ترجیح میدهند SCD را به لایه Gold موکول کنند، ولی اگر اطلاعات تاریخی باید نزدیک به منبع بماند، مثلاً برای تطابق با لاگهای اپلیکیشن یا دادههای NoSQL پیادهسازی آن در Silver ضروری میشود.
استفاده از کلیدهای جایگزین (Surrogate Keys)
کلیدهای جایگزین شناسههای مصنوعی (غیربیزینسی) هستند که برای یکتاسازی رکوردها استفاده میشوند. آنها پایدار و بدون تغییر هستند. بر خلاف business keyها که از دامنه واقعی میآیند (مثل شماره مشتری)، Surrogate Key معمولاً بهصورت عددی و داخلی تولید میشود (auto increment, UUID, hash, …). از مزایا آن میتوان گفت:
- ردیابی بهتر تغییرات در ابعاد تاریخی (SCD)
- استقلال از تغییرات در کلیدهای واقعی (Business Keys)
اما دیدگاه غالب در معماری مدالیون این است که کلیدهای جایگزین بهتر است در لایه Gold ساخته شوند. زیرا Silver عمدتاً لایهای برای پالایش و مصرفپذیری اولیه است، نه برای ساخت dimension model. اگر با این حال لازم بود از کلیدهای جایگزین در Silver استفاده کنید، باید: سازوکار هماهنگی با کلیدهای Gold را دقیق طراحی کنید و از ناسازگاری کلیدها در مراحل بعدی جلوگیری کنید
در نهایت، طراحی مدل داده در لایه Silver بیش از آنکه فقط یک تمرین فنی باشد، یک تمرین استراتژیک است. تصمیمهایی که در این لایه گرفته میشوند، بر موفقیت کل چرخه تحلیلی اثرگذارند. پرسشهایی کلیدی که باید پاسخ دهید: آیا Silver فقط لایهای برای staging بهبود یافته است؟ یا لایهای برای مصرف مستقیم در تحلیلها و گزارشها؟ چقدر اجازه دارید غیرنرمالسازی انجام دهید؟ چه تاریخچهای باید در این لایه نگهداری شود؟ آیا باید دادهها در این لایه به دادههای مرجع یا سایر منابع غیراصلی غنیسازی (enrichment) شوند یا نه؟ اگر پاسخ این پرسشها با دیدی استراتژیک داده شود، لایه Silver به ستون فقرات معماری دادهتان تبدیل خواهد شد، پلی پایدار و هوشمند میان دادههای خام و بینشهای نهایی.
یکپارچهسازی با سایر منابع
یکی از سؤالات کلیدی در طراحی لایه Silver این است که آیا در همین مرحله باید دادهها از منابع مختلف با یکدیگر ترکیب شوند یا نه؟ آیا باید نمایی یکپارچه و سازمانی (Enterprise View) از مشتری، سفارش، پرداخت و دیگر موجودیتها ساخته شود، یا این ادغام بهتر است به لایههای بعدی موکول شود؟ پاسخ این سؤال نه مطلقاً مثبت است و نه منفی؛ بلکه بستگی زیادی به معماری دادهی سازمان، نیازهای تحلیلی، و رویکرد آن نسبت به مالکیت دامنهای دادهها دارد.
در بسیاری از معماریهای مدرن داده، از جمله معماری مدالیون و بهویژه Data Mesh، رویکرد پیشنهادی آن است که در لایه Silver دادهها همچنان با مرزبندی مشخص و بدون ادغام باقی بمانند. این یعنی دادههایی که از سیستمهای عملیاتی متفاوت، مثل CRM، مالی، لجستیک یا مارکتینگ، وارد میشوند، باید در جدولها و مدلهای جداگانه پردازش شوند. این تفکیک، مزایای متعددی دارد:
- ایزولهسازی وابستگیها (Isolation of Concerns): دادهی ناقص یا ناسالم از یک سیستم، تأثیر ناخواستهای بر تحلیلهای وابسته به سیستم دیگر نخواهد داشت.
- سهولت در پاکسازی، پالایش و تست مستقل دادهها: هر منبع داده را میتوان جداگانه اعتبارسنجی و کنترل کیفیت کرد، بدون نگرانی از تأثیر آن بر دیگر جداول.
- همراستایی با معماری دامنهمحور: در معماریهایی مانند Data Mesh، حفظ مالکیت داده در سطح دامنه (Domain Ownership) اصل بنیادی است، و ترکیب زودهنگام دادهها ممکن است با این اصل در تضاد باشد.
به عنوان مثال اگر دادههای کاربران از سیستم CRM و اطلاعات پرداختها از سیستم مالی بهسرعت با یکدیگر ترکیب شوند، اختلال در یکی ممکن است باعث اختلال در دیگری شود، حتی اگر وابستگی تحلیلی میان آنها وجود نداشته باشد. اما در عمل، بسیاری از سازمانها بنا به شرایط خاص خود تصمیم میگیرند Harmonization را در همین لایه Silver پیادهسازی کنند. در این سناریو، لایه Silver بهجای یک لایه صرفاً پاکسازیشده، نقش یک لایه یکپارچهسازی سنتی دادهها (Traditional Data Integration Layer) را ایفا میکند؛ یعنی دادههای کاربران، تراکنشها، سفارشات، مکان، تبلیغات و سایر موجودیتها از منابع مختلف با هم ترکیب شده و مدلهای جامعتری برای مصرف اولیه ساخته میشود.
برای این منظور، معمولاً از مدلسازیهای ساختیافتهتری استفاده میشود، از جمله:
- فرم نرمال سوم (Third Normal Form – 3NF): جداول بهگونهای طراحی میشوند که هر موجودیت، ساختار منطقی مستقل خود را داشته باشد و از افزونگی داده جلوگیری شود. این فرم برای مدلسازیهای پایگاهدادههای رابطهای سنتی بسیار رایج است.
- مدل Data Vault: با ساختار سهگانهی Hub, Link و Satellite، این مدل امکان ذخیرهسازی دادههای خام با انعطافپذیری بالا و مقاومت در برابر تغییرات را فراهم میکند. Data Vault مناسب محیطهاییست که دادهها مکرراً تغییر میکنند و نگهداری تاریخچه اهمیت دارد.
تصمیمگیری دربارهی اینکه Harmonization در Silver انجام شود یا به Gold سپرده شود، وابسته به عواملی چون:
- میزان دسترسی به منابع اصلی: اگر دسترسی به سیستمهای منبع محدود یا پرهزینه است (مثلاً در SaaS یا پایگاههای داده برونسپاریشده)، ممکن است ترجیح داده شود که ادغام در Silver انجام شود تا از بارگیری مجدد داده جلوگیری شود.
- نیازهای فوری تحلیلی یا عملیاتی: برخی مدلهای یادگیری ماشین یا گزارشهای روزانه نیاز به دید یکپارچه دارند که تأخیر در ساخت آن، پروژه را مختل میکند.
- توان فنی و منابع تیم داده: اگر تیم فاقد تخصص یا زیرساخت کافی برای طراحی و نگهداری لایه Gold باشد، ممکن است ترجیح دهد ساخت مدلهای ادغامیافته را در Silver انجام دهد.
بنابراین، هیچ پاسخ واحدی برای Harmonization وجود ندارد. اگرچه تفکیک منابع در Silver، طراحی را ایزولهتر، مقیاسپذیرتر و قابلمدیریتتر میکند، اما در برخی شرایط ادغام زودهنگام میتواند منطقی یا حتی ضروری باشد. اگر تصمیم به انجام Harmonization در Silver گرفتید، باید با آگاهی کامل، مستندسازی دقیق، و نگاه بلندمدت آن را اجرا کنید. چرا که در چنین حالتی، Silver از نقش اولیهاش فاصله میگیرد و بهنوعی جایگزین لایه Gold یا حتی لایههای Integration در معماری سنتی میشود.
تحلیلهای عملیاتی (Operational Querying) و مدلهای یادگیری ماشین
در بسیاری از سازمانها، لایه Silver بهعنوان نخستین نقطهی ورود داده به کاربردهای عملیاتی و مدلهای یادگیری ماشین استفاده میشود. این لایه بهدلیل ساختار پاکسازیشده، استانداردسازی اولیه و جداسازی مناسب منابع، زمینهای مناسب برای تحلیلهای روزمره، گزارشگیریهای دقیق و شروع فرآیندهای هوش مصنوعی فراهم میکند. با این حال، استفاده از Silver برای این اهداف همواره با یک پرسش کلیدی همراه است: آیا در همین لایه باید دادهها را برای یادگیری ماشین غنیسازی کنیم، یا این وظیفه باید به لایهای مجزا و تخصصی سپرده شود؟
مدلهای یادگیری ماشین زمانی بهترین عملکرد را دارند که دادههای آموزشی آنها با بافت واقعی مسئلهی کسبوکار همراستا باشند. از این رو، برخی تیمها تمایل دارند غنیسازی داده را زودتر آغاز کنند، مثلاً با تبدیل ویژگیهای دستهای (categorical) به مقادیر عددی یا استخراج ویژگیهای مشتقشده (derived features). این اقدامات موجب سادهتر شدن پردازش دادهها توسط الگوریتمهای یادگیری ماشین و بهبود کیفیت مدلها میشود. در همین راستا، معماری دادهی برخی سازمانها فراتر از مدل کلاسیک سهلایهای رفته و لایهای مجزا برای مهندسی ویژگی (feature engineering)، تست مدلها یا اجرای سناریوهای آزمایشی ایجاد میکنند که گاهی با عنوان sandbox یا machine learning layer شناخته میشود.
با این حال، تصمیمگیری درباره مکان مناسب برای اعمال این غنیسازیها، به شدت به نوع کاربرد، پیچیدگی دادهها و ترجیحات تیم فنی وابسته است. اگر هدف اصلی اجرای گزارشهای عملیاتی است که به دادههای غنیشده نیاز دارند، شروع فرآیند enrichment در Silver منطقی است. هرچند این کار ممکن است پیچیدگیهایی در هنگام merge در لایه Gold ایجاد کند، اما انعطافپذیری بالاتری به تیمهای مصرفکننده میدهد و میتواند زمان رسیدن به بینش را کاهش دهد.
در مقابل، اگر ترجیح میدهید ساختار دادهها را ساده و ایزوله نگه دارید، برای مثال بهمنظور سهولت نگهداری یا بهحداقل رساندن وابستگیهای بین تیمی، میتوانید غنیسازی را به لایه Gold موکول کنید. این رویکرد به تفکیک مسئولیتها کمک میکند و موجب مدیریتپذیری بهتر در سیستمهایی با پیچیدگیهای بالا میشود، بهویژه در محیطهایی که دادهها از دامنههای مختلف میآیند یا تغییرات ساختاری مکرر رخ میدهد.
در نهایت، انتخاب زمان و محل غنیسازی دادهها باید بر مبنای ملاحظات فنی و عملیاتی، نوع بار کاری (workload)، و اهداف کسبوکاری انجام شود. لایه Silver با اینکه محلی مناسب برای شروع است، نباید بهتنهایی بار تمام پردازشهای هوشمند را بر دوش بکشد؛ بلکه باید بهعنوان نقطهای منعطف در معماری در نظر گرفته شود که بر اساس نیاز، قابلیت گسترش، جداسازی یا غنیسازی بیشتر را دارد.
اتوماتسازی وظایف و تسکها
در مسیر ساخت یک معماری داده مقیاسپذیر، اتوماتیک کردن تسکها نهتنها یک انتخاب، بلکه یک ضرورت است. با این حال، باید درک کنیم که در معماری مدالیون، همهی مراحل پردازش به یک میزان قابل استانداردسازی یا اتوماتیک کردن نیستند. برخی مراحل بهویژه در ارتباط با سیستمهای منبع، چالشبرانگیزتر و متنوعتر از سایر بخشها هستند و همین موضوع نیازمند رویکردهای متفاوت در طراحی ابزارها و چارچوبهای اتوماسیون است.
بخش آغازین این مسیر، یعنی انتقال داده از سیستمهای مبدأ به لایه Bronze، یکی از دشوارترین قسمتها در فرآیند اتوماتیک کردن محسوب میشود. دلیل این دشواری، تنوع زیاد فناوریها، فرمتها و راهکارهای ارائهشده توسط فروشندگان مختلف (vendors) در سمت سیستمهای عملیاتی است. برای مثال، ممکن است برخی سیستمها تنها از طریق APIهای اختصاصی یا فرمتهای خاص مانند CSV داده ارائه دهند؛ در نتیجه، تیم داده ناچار است فرایند ingestion را با این تنوع بالا تطبیق دهد، که اغلب مستلزم کدنویسی سفارشی و مدیریت فرمتهای متنوع است.
اما وقتی این مانع اولیه پشت سر گذاشته شد و دادهها بهصورت استاندارد (برای مثال در قالب Delta Lake) در لایههای Bronze و سپس Silver ذخیره شدند، امکان استانداردسازی و اتوماتیک کردن بهمراتب بالاتری فراهم میشود. در این مرحله، ابزارها و چارچوبهای مبتنی بر متادیتا نقش حیاتی ایفا میکنند. از آنجا که وظایف در این لایه عمدتاً شامل تبدیل نام ستونها، اعمال فیلترها، پاکسازی داده، استفاده از جدولهای lookup و مقداردهی پیشفرض است، ماهیت تکرارشونده و قابل پیشبینی این فعالیتها زمینهای مناسب برای اتوماسیون فراهم میکند.
یکی از رویکردهای رایج در این فاز، استفاده از metadata-driven frameworks است؛ در این رویکرد، اطلاعاتی مانند اسکیمای داده، قواعد کیفیت، کلیدهای طبیعی و تجاری، و قوانین نگاشت (mapping rules) همگی در یک مخزن متادیتا ثبت میشوند. سپس ابزارهای اتوماسیون بر اساس این مخزن، کدهای تبدیل داده را بهصورت خودکار تولید میکنند. این یعنی تنها با بهروزرسانی متادیتا، میتوان رفتار pipeline را بدون نیاز به تغییر دستی در کدها اصلاح کرد.
از میان ابزارهای مطرح در این زمینه میتوان به dbt اشاره کرد، ابزاری متنباز که امکان تعریف تبدیلها را در قالب قالبهایی شبیه به کوئریهای SQL فراهم میسازد. این ابزار بهویژه برای ساخت pipelineهای تحلیلی سبک و مبتنی بر SQL بسیار کاربردی است. در محیطهای مبتنی بر Databricks، چارچوب Delta Live Tables (DLT) نیز گزینهای قدرتمند است که علاوه بر تعریف تبدیلها، وظایفی مانند ارکستراسیون وظایف، مدیریت خوشهها، پایش کیفیت داده، و مدیریت خطا را نیز بر عهده میگیرد و فرآیند end-to-end را تا حد زیادی اتوماتیک میسازد.
در مرحلهی نهایی، یعنی ارائه داده به مصرفکنندگان نهایی، میزان اتوماتیک کردن به چالش کشیده میشود. اینجا اغلب با منطقهای تجاری پیچیده، شرایط خاص و وابستگیهای بینسیستمی روبهرو هستیم که بهسختی میتوان آنها را تنها از طریق متادیتا مدلسازی کرد. با این حال، استفاده از قالبها (templates) و سرویسهای بازقابلاستفاده (reusable services) میتواند تا حدودی این پیچیدگیها را کاهش داده و سطحی از استانداردسازی را ممکن کند.
در نهایت، کلید موفقیت در طراحی یک معماری داده مقیاسپذیر، درک تفاوتهای ذاتی مراحل مختلف پردازش، و انتخاب هوشمندانهی ابزارهای اتوماسیون متناسب با هر مرحله است. با بهکارگیری مؤثر این چارچوبها، میتوان pipelineهای داده را به گونهای طراحی کرد که نهتنها پایدار و مقاوم باشند، بلکه در برابر رشد و تغییرات آینده نیز منعطف باقی بمانند.
لایه Silver در عمل
در معماری مدالیون، مسیر دادهها از لایه Bronze آغاز میشود؛ جایی که دادههای خام از منابع گوناگون، بدون هیچگونه تغییر یا دستکاری، بارگذاری و ذخیره میشوند. هدف از این مرحله، حفظ ساختار اولیه و اصالت دادههاست، موضوعی حیاتی برای رعایت الزامات تطبیقپذیری (compliance)، قابلیت ردیابی (traceability) و امکان ارجاع به منبع اصلی. اما این تنها آغاز راه است؛ زیرا دادههای خام معمولاً برای تحلیل یا استفاده عملیاتی مستقیم، مناسب نیستند.
در گام بعد، یعنی لایه Silver، وظیفه اصلی پالایش (cleansing)، استانداردسازی (standardization) و در برخی موارد، غنای جزئی دادهها (slight enrichment) است. در این لایه، دادهها از حالت خام خارج شده و با اعمال حداقل تغییرات مورد نیاز، به فرمتی تبدیل میشوند که قابل استفاده، قابل کوئریگیری و آمادهی پردازشهای بعدی در لایه Gold باشد. این تغییرات میتوانند شامل اصلاح فرمتها، رفع ناسازگاریها، حذف مقادیر نامعتبر یا تکراری، اعتبارسنجی با دادههای مرجع، و اعمال چکهای کیفیت داده باشند. همهی این اقدامات با هدف آمادهسازی داده برای مصارف بعدی، بدون پیچیدهسازی غیرضروری انجام میگیرد.
ساختار دقیق لایه Silver ممکن است در سازمانهای مختلف، شکلهای متفاوتی به خود بگیرد. در سادهترین حالت، این لایه بازنمایی دقیقی از دادههای لایه Bronze است، با این تفاوت که دادهها پاکسازی و استاندارد شدهاند. همین ساختار ساده برای بسیاری از سازمانها کافی و مؤثر است. اما در شرایط پیچیدهتر، ممکن است نیاز باشد این لایه به مراحل متعدد تقسیم شود. برای مثال، اگر هدف افزایش قابلیت ممیزی (auditability) باشد، میتوان آن را به سه مرحلهی مجزا تقسیم کرد: یکی برای پاکسازی، دیگری برای تطبیق با استانداردهای داده، و سومی برای ساخت ساختارهای تاریخچهای مانند SCD.
در مواردی که سازمان نیاز دارد همزمان مالکیت داده را بر اساس سیستمهای منبع حفظ کرده و دادهها را یکپارچه نیز کند، میتوان دو زیرلایه مستقل در Silver تعریف کرد: یکی برای دادههای پاکسازیشده که منطبق با ساختار سیستمهای منبع هستند، و دیگری برای دادههایی که بهصورت همگامسازیشده و ادغامشده (harmonized) درآمدهاند. این تفکیک، ضمن حفظ شفافیت در ساختار لایهها، امکان کنترل و انعطافپذیری بیشتری را فراهم میسازد. انعطاف ساختاری Silver به آن اجازه میدهد تا نهتنها نیازهای فعلی پردازش داده را برآورده سازد، بلکه قابلیت مقیاسپذیری و انطباق با نیازهای آتی را نیز داشته باشد. با توجه به تعداد منابع داده، سطح پیچیدگی، و نیازهای عملکردی خاص هر سازمان، این لایه میتواند طراحیهای متنوعی به خود بگیرد.
اکنون که دادهها پاکسازی و ساختار یافته شدهاند، نوبت به لایه Gold میرسد، جایی که دادهها به ارزشمندترین شکل خود تبدیل میشوند. در این مرحله، دادهها با اعمال منطقهای تجاری، مدلسازیهای پیچیده، و تجمیعهای هدفمند، به اطلاعاتی قابل تفسیر برای تصمیمسازیهای استراتژیک تبدیل میشوند. اینجاست که تحلیلهای عملیاتی، داشبوردهای مدیریتی، و مدلهای پیشبینی بر بستر دادههایی بنا میشوند که مسیر خود را از خامترین تا قابل اعتمادترین شکل طی کردهاند.
لایهی Gold در معماری مدالیون
در معماری مدالیون، لایهی Gold آخرین ایستگاه در مسیر تحول دادههاست؛ جایی که دادهها پس از گذر از مراحل دریافت، پاکسازی و استانداردسازی در لایههای Bronze و Silver، اکنون به شکلی تحلیلپذیر، بهینهشده و غنیشده در اختیار تیمهای تصمیمساز قرار میگیرند. این لایه نهتنها به لحاظ فنی پیچیدهترین بخش معماری داده است، بلکه از نظر تجاری نیز حیاتیترین است؛ چرا که خروجی آن مستقیماً در گزارشها، داشبوردهای مدیریتی، الگوریتمهای یادگیری ماشین و تحلیلهای استراتژیک سازمان مورد استفاده قرار میگیرد.
دادههایی که وارد این لایه میشوند، باید نمایی تلفیقی از اطلاعات موجود در منابع مختلف را ارائه دهند؛ نمایی که ضمن همگون بودن، پاسخگوی نیازهای متنوع کاربران نیز باشد. اما این کار سادهای نیست. پیچیدگی لایهی Gold عمدتاً از تلاش برای ادغام دادههایی ناشی میشود که از سیستمهایی با ساختار، قواعد و کیفیت متفاوت سرچشمه گرفتهاند. باید میان کلیدهای کسبوکار، دستهبندیهای زمانی و مکانی، و قواعد محاسباتی هر منبع، هماهنگی برقرار کرد، کاری که مستلزم بهکارگیری منطقهای تجاری پیچیده، پاکسازی پیشرفته، و اعمال لایههای مختلف از تجمیع و غنیسازی است.
کاربران این لایه نیز تنوع زیادی دارند. تحلیلگران کسبوکار عموماً به جداول ساده و تخت نیاز دارند تا بتوانند به سرعت کوئریهای خود را اجرا کنند. در مقابل، متخصصان داده معمولاً مدلهای تحلیلی پیچیدهتری همچون طرح ستارهای (Star Schema) را ترجیح میدهند تا بتوانند تحلیلهای چندبعدی انجام دهند. تیمهای گزارشگیری نیز ممکن است به نماهای زمانمحور یا بر اساس شاخصهای عملکرد نیاز داشته باشند. این تنوع در نیازها طراحی لایهی Gold را به فرآیندی چندوجهی تبدیل میکند که باید هم از نظر فنی مقیاسپذیر باشد و هم از نظر مفهومی با منطقهای سازمانی همراستا بماند.
برای مدیریت این پیچیدگی، اغلب معماری لایهی Gold به شکل چندمرحلهای طراحی میشود. در مرحلهی نخست، دادهها خلاصهسازی میشوند و محاسبات اولیه انجام میگیرد. سپس، قواعد تجاری خاص سازمان روی آنها اعمال میشود، قواعدی که میتوانند شامل منطقهای مربوط به مثلا اعمال تخفیف، دستهبندی مشتریان یا تفسیر مقادیر غیراستاندارد باشند. در نهایت، نماهای نهایی برای استفاده در ابزارهای تحلیل یا گزارشگیری ایجاد میشود؛ نماهایی که باید دقیق، قابل اعتماد و سریعالاجرا باشند.
یکی از روشهای رایج و مؤثر در طراحی این لایه، مدلسازی ستارهای است. در این مدل، یک جدول Fact برای نگهداری رویدادهای کلیدی مانند تراکنشها یا سفارشها تعریف میشود و جداول Dimension مختلفی، اطلاعات توصیفی مربوط به مشتری، محصول، زمان، منطقه و… را ذخیره میکنند. این ساختار به دلیل سادگی در درک، کارایی بالا در کوئریها و امکان تعریف شاخصهای تحلیلی، انتخاب محبوبی در معماریهای دادهمحور به شمار میرود.
با این حال، طراحی مدل ستارهای نیز محدود به ساختار پایه نیست. در عمل، بهمرور زمان نیاز به قابلیتهایی مانند ثبت تغییرات تاریخی (SCD Type 2)، Snapshot Fact Tables، جداول Point-in-Time برای تطابق دقیق با زمان وقوع رویدادها، و پلهای زمانی برای مدیریت پیچیدگی تحلیلی افزایش مییابد. بهکارگیری این ساختارهای پیشرفته، قدرت مدل را در پاسخگویی به سؤالات تحلیلی افزایش میدهد، اما طراحی، مستندسازی و نگهداری آنها نیازمند دقت و تجربه بالاست.
نکتهی مهم آن است که لایهی Gold یک قالب یکسان ندارد. بسته به نیازهای خاص سازمان، این لایه ممکن است شامل جداول سادهی تخت، مدلهای چندبعدی، نماهای مبتنی بر ساختارهای JSON یا حتی نماهای گرافی باشد. برخی سازمانها نیز نماهای از پیش تجمیعشده و آمادهی مصرف برای الگوریتمهای یادگیری ماشین تعریف میکنند تا نیازهای تحلیلی پیشرفته را پوشش دهند. در همهی این موارد، هدف آن است که طراحی لایهی Gold بهگونهای انجام شود که با الگوهای مصرف داده در سازمان و نیازهای کاربران نهایی بیشترین تطابق را داشته باشد.
در مجموع، لایهی Gold جایی است که دادهها به ارزش تجاری واقعی بدل میشوند. تمام تلاشهایی که در لایههای قبل برای حفظ کیفیت، یکپارچگی و انعطافپذیری دادهها صرف شده، در این نقطه به ثمر مینشیند. طراحی ضعیف این لایه میتواند کل معماری داده را ناکارآمد کند، در حالی که طراحی هوشمندانه و دقیق، مسیر تصمیمسازی و تحلیل در سازمان را متحول خواهد کرد. در ادامه، وارد جزئیات طراحی مدل ستارهای و پاسخ به چالشهای رایج آن خواهیم شد.
مدل Star Schema
در معماری مدالیون، مدل ستارهای نقشی کلیدی در لایه Gold ایفا میکند؛ جایی که دادههای پالایششده باید در قالبی ساده، ملموس و منطبق با ذهنیت کاربران نهایی سازماندهی شوند. هدف این مدل، تنها عملکرد بالا نیست، بلکه ایجاد مدلی تحلیلی است که کاربران تجاری بتوانند با آن تعامل مؤثر داشته باشند. هستهی مدل ستارهای یک جدول مرکزی fact است که توسط چندین جدول dimension احاطه شده است. جدول fact اطلاعات رویدادها یا تراکنشها را ذخیره میکند و هر سطر آن به مقادیر توصیفی در dimensionها ارجاع دارد. برای نمونه در یک شرکت هواپیمایی:
- fact_flight_sales: شامل اطلاعات فروش بلیت، مبلغ، زمان خرید
- dim_customer: اطلاعات مشتری
- dim_flight: اطلاعات پرواز
- dim_aircraft: نوع هواپیما
- dim_time: ابعاد زمانی
ساخت این مدل از گفتوگو با ذینفعان آغاز میشود: شاخصهای مهم کسبوکار چیست؟ چه گزارشهایی باید تولید شوند؟ پس از آن، سطح جزئیات (granularity) مشخص میشود و بر اساس آن، dimensionها و مقادیر fact تعریف میگردند.
در فرآیند لود داده، ابتدا دادهها در staging table پاکسازی و استانداردسازی میشوند، سپس به جدولهای اصلی منتقل میگردند. برای dimensionهایی که اطلاعاتشان در طول زمان تغییر میکند، از تکنیک Slowly Changing Dimension (SCD Type 2) استفاده میشود:
- مقایسه رکورد جدید با business key
- در صورت تغییر، درج نسخه جدید با surrogate key جدید و غیرفعالسازی نسخه قبلی
- درج رکورد جدید اگر قبلاً وجود نداشته باشد
همچنین استفاده از شناسهی سیستم منبع (Source System ID) و استانداردسازی فیلدها (Harmonization) مانند پر کردن nullها یا رمزگشایی کدها نیز ضروری است. در جدول fact، هر رکورد باید با surrogate keyهای متناظر به dimensionها وصل شود. اگر رکورد fact زودتر از dimension وارد شود (early arriving facts)، از placeholderها برای حفظ انسجام مدل استفاده میشود.
مدل ستارهای تنها یک الگوی فنی نیست؛ بلکه زبان مشترکی میان تیمهای داده و کسبوکار ایجاد میکند. اگر بهدرستی طراحی شود، پلی مؤثر خواهد بود میان دادهی خام و بینش قابلاتکا. با این حال، اجرای آن در مقیاس سازمانی نیازمند ساختاردهی چندمرحلهای، مدیریت تغییرات، تطبیق با معماری دامنهای و انطباق با ابزارهای تحلیلی متنوع است. در بخش بعد، به مدلها و رویکردهایی میپردازیم که بهعنوان جایگزین یا مکمل مدل ستارهای برای سادهسازی یا غنیسازی معماری Gold استفاده میشوند.
انواع لایهها
در حالی که استفاده از مدل ستارهای متشکل از جداول fact و dimension یکی از محبوبترین رویکردها برای طراحی لایهی Gold محسوب میشود، اما در عمل با گسترش ابعاد مدل، افزایش منابع داده و رشد نیازهای تحلیلی، این ساختار بهتدریج دچار پیچیدگیهای جدیدی میشود. بهویژه زمانی که سازمانها به دنبال پاسخگویی به نیازهای مشابه اما با تفاوتهای جزئی هستند، ممکن است طراحی لایهی Gold یا حتی Silver را متناسب با این تفاوتها بازنگری کنند.
در بسیاری از سازمانهای بزرگ، این بازطراحی با افزودن لایههایی تحت عنوان Curated»، «Semantic یا حتی «Platinum» انجام میشود. این لایهها به عنوان زیرلایههایی تخصصیتر از Gold معرفی میشوند و هدفشان ارائهی دادههایی غنی، هماهنگ، قابل استفاده مجدد، و با معنای تجاری مشخص برای کاربران نهاییست. بهطور خاص، در چنین معماریهایی معمولاً چند اصل کلیدی رعایت میشود:
- ایجاد جداول مرجع استاندارد و «Conformed Dimensions» که در سراسر دیتا مارتهای مختلف مشترک هستند. این ابعاد هماهنگ (مثلاً مشتری، زمان، محصول) در هر مارت معنای یکسانی دارند و از دوبارهکاری یا تکرار تعریفها جلوگیری میکنند.
- توسعهی لایهی معنایی (Semantic Layer) برای ارائهی نماهایی قابل فهم و با مفاهیم تجاری مشخص به ابزارهای گزارشگیری و مصورسازی مانند Power BI یا Tableau. این لایه نقش یک واسط ترجمهگر بین دادهی خام و کاربران نهایی را ایفا میکند.
- طراحی «Platinum Layer» به عنوان دقیقترین و پالایششدهترین نسخهی داده، مناسب برای موارد مصرف بسیار خاص، تحلیلهای حساس یا نیاز به انطباق کامل با استانداردهای کنترلی و نظارتی.
اگرچه پیادهسازی این لایهها نیازمند تلاش زیادی است، اما مزایای آنها، مانند کاهش مغایرت بین تیمها، افزایش استفادهپذیری داده، و انسجام معنایی در کل سازمان، برای شرکتهای بزرگ بسیار چشمگیر است. البته استفاده از این ساختارها باید با در نظر گرفتن عواملی همچون اندازه سازمان، تنوع منابع داده، سطح نیاز به مفاهیم معنایی، و الزامات امنیتی و قانونی انجام شود. در برخی موارد، بهدلیل نیازهای خاص، سازمانها ترجیح میدهند از ساختار سادهتری مانند «One Big Table» استفاده کنند که در ادامه بررسی خواهد شد.
مدل One-Big-Table (OBT)
مدل One-Big-Table (OBT) یکی از رویکردهای سادهسازی در معماری داده است که بهجای تفکیک اطلاعات در جداول fact و dimension، همهچیز را در یک جدول واحد قرار میدهد. این رویکرد بهویژه در فازهای ابتدایی پروژه، برای تیمهای کوچک یا در سناریوهایی با نیاز به توسعهی سریع، بسیار مفید است. در OBT، اطلاعات از منابع مختلف میتوانند بهشکل مسطح (flat) یا تو در تو ذخیره شوند. بهعنوان مثال، ستون «محصولات» میتواند شامل یک آرایه از آیتمها باشد که کل اطلاعات سفارش را در یک ردیف نگه میدارد. این سادگی مزایایی دارد مانند:
طراحی سریعتر ETL
- حذف join و بهبود عملکرد در برخی کوئریها
- انعطافپذیری در برابر تغییر نیازمندیها
- سازگاری بیشتر با ابزارهای علم داده
- سهولت در تحلیلهای long-term یا سریزمانی
اما این مدل بدون مشکل نیست. تکرار اطلاعات در هر ردیف باعث افزونگی داده و افزایش شدید حجم جدول میشود. همچنین تحلیل دادههای تو در تو (مثل محاسبه مجموع فروش در آرایهها) به عملیات سنگینی مانند explode نیاز دارد که ممکن است عملکرد را بدتر از چندین join کند. نگهداری چنین ساختاری، بهویژه در هنگام تغییر schema یا بروزرسانی داده، دشوار و منابعبر خواهد بود.
در عمل، OBT بیشتر برای موارد زیر توصیه میشود:
- تیمهای فاقد تخصص در مدلسازی پیچیده
- تحلیلهای سریع، اثبات مفهوم (PoC)، یا داشبوردهای ساده
- پیشپردازش دادهها برای یادگیری ماشین
اما در پروژههایی که به پایداری، مقیاسپذیری، انعطافپذیری و استانداردسازی نیاز دارند، مدلهای ابعادی مانند ستارهای گزینهای مناسبتر هستند. در نهایت، OBT و مدل ستارهای را نباید الزاماً در تقابل با هم دید. در بسیاری از معماریهای مدرن، این دو بهصورت مکمل استفاده میشوند: OBT برای چابکی و سرعت، و مدل ستارهای برای ساختاردهی اصولی و تحلیلهای پایدار. انتخاب بین این دو، تصمیمی استراتژیک است و باید بر اساس اهداف، ابزارها و ظرفیت تیم اتخاذ شود.
لایه Serving
لایه Serving آخرین ایستگاه در معماری لیکهاوس است؛ جایی که دادههای پالایششده از لایههای Gold، Silver و Bronze به دست مصرفکنندگان واقعی میرسند، نه لزوماً با کوئری مستقیم، بلکه از طریق ارائهی داده در قالبها و محیطهایی که برای کاربران آشنا، امن و قابل استفاده باشد. اگرچه دادهها در لایهی Gold مدلسازی شدهاند، اما بسیاری از واحدهای سازمانی توانایی یا تمایل تعامل مستقیم با محیط فنی لیکهاوس (مثل Spark یا Delta Lake) را ندارند. Serving Layer این شکاف را پر میکند: دادهها را به ابزارهایی مانند PostgreSQL، Power BI، ClickHouse، Druid یا Neo4j منتقل میکند تا مصرف آن برای گروههای مختلف، ساده، سریع و مطابق با نیازشان باشد. برای مثال، واحدی که به PostgreSQL وابسته است، میتواند دادهی تحلیلشده را از یک دیتامارت داخلی دریافت کند، بدون درگیری با پیچیدگیهای لیکهاوس. یا در Power BI، معمولاً دادهها در Import Mode لود میشوند تا امنیت، سرعت و پایداری تحلیلها حفظ شود. Serving Layer در واقع پلی است میان دنیای پردازشهای سنگین و کاربران نهایی. این لایه با فراهمسازی انعطاف در نحوهی ارائهی داده، نقش کلیدی در کاربردپذیر کردن ارزش دادهها ایفا میکند و به سازمان اجازه میدهد تا دادهی آمادهی تحلیل را دقیقاً در قالب دلخواه مصرفکننده ارائه کند.
لایهی Gold در عمل
در معماری مدالیون، لایهی Gold بهعنوان حلقهی نهایی در زنجیرهی پالایش و مدلسازی داده، جاییست که دادهها به شکلی ساختیافته، بهینه و آمادهی استفاده برای تحلیلهای پیشرفته و تصمیمگیریهای کلان در اختیار سازمان قرار میگیرند. اما اهمیت این لایه تنها در جنبههای فنی یا مدلسازی نیست، بلکه ارزش واقعی آن زمانی آشکار میشود که طراحی آن با سیاستهای حاکمیت داده همسو باشد و بهصورت واقعی در خدمت نیازهای عملیاتی و استراتژیک کسبوکار قرار گیرد. برای دستیابی به چنین هدفی، طراحی لایهی Gold باید در تعامل تنگاتنگ با قواعد و الزامات حاکمیت داده انجام شود. این تعامل شامل مستندسازی دقیق و کاتالوگسازی همهی مجموعهدادهها، شفافسازی چگونگی و چرایی استفاده از داده توسط کاربران مختلف، تخصیص داده به موارد استفادهی مشخص، و تعریف دقیق نقشها و مسئولیتها برای تضمین امنیت و جلوگیری از استفادههای نادرست است. این رویکرد نهتنها انطباق با الزامات قانونی و استانداردهای صنعتی را ممکن میسازد، بلکه باعث ایجاد اعتماد در میان تحلیلگران و مصرفکنندگان داده میشود. در واقع، همین هماهنگی است که لایهی Gold را از صرفاً یک مخزن داده به مرجع طلایی دادههای معتبر و قابل اتکای سازمانی تبدیل میکند.
در کنار این جنبهی حاکمیتی، یکی از اصول بنیادین در طراحی مدل داده در این لایه، وضوح، سادگی و بهینگی ساختار است. کاربران نهایی، اعم از تحلیلگران، توسعهدهندگان یا تیمهای محصول، باید بتوانند بدون نیاز به مستندات پیچیده، ماهیت دادهها را بهدرستی درک کرده و از آن بهره ببرند. این هدف زمانی محقق میشود که ساختار جداول، نامگذاری ستونها و روابط میان آنها به گونهای طراحی شود که خودتوضیح (self-explanatory) و خوانا باشند. همچنین، دادهها باید برای پردازش تحلیلی بهینه شده باشند، بهنحوی که سرعت، مقیاسپذیری، و عملکرد مناسبی در ابزارهای گزارشگیری و تحلیلهای پیشرفته داشته باشند. مدل طراحیشده نیز باید طیف متنوعی از use caseها را پوشش دهد، از داشبوردهای مدیریتی و تحلیلهای مالی گرفته تا الگوریتمهای یادگیری ماشین یا پردازشهای گرافی پیچیده.
در عمل، پاسخگویی به این تنوع نیازها باعث میشود که لایهی Gold، برخلاف تصور اولیه، لایهای یکتا و یکپارچه نباشد، بلکه از چندین زیرلایه یا ساختار فیزیکی موازی تشکیل شود. این زیرلایهها ممکن است بسته به نوع کاربری، عملکرد یا تیمهای مصرفکنندهی داده طراحی شوند؛ برای مثال یک نسخهی سادهشده از داده برای استفاده در ابزارهای بصریسازی، یا نسخهای غنیتر و با جزییات برای مدلهای یادگیری ماشین.
در مسیر طراحی چنین لایهای، هیچ الگوی واحدی وجود ندارد که برای تمام سازمانها کاربرد داشته باشد. برخی از تیمها از الگوهای کلاسیک مانند مدل ستارهای (Star Schema) استفاده میکنند، چرا که این مدلها برای ساخت دیتامارتهای تحلیلی و استفاده در ابزارهای BI بهخوبی جواب میدهند. در مقابل، بعضی سازمانها رویکرد سادهتری مانند مدل One-Big-Table را انتخاب میکنند تا سرعت توسعه را بالا ببرند یا نیاز تیمهای علم داده را راحتتر پاسخ دهند. در مواردی نیز لایههایی تخصصیتر مانند لایههای معنایی یا پلاتینوم (Semantic and Platinum Layer) طراحی میشوند تا داده را برای مخاطبان خاص، به شکلی هدفمندتر سرویسدهی کنند.
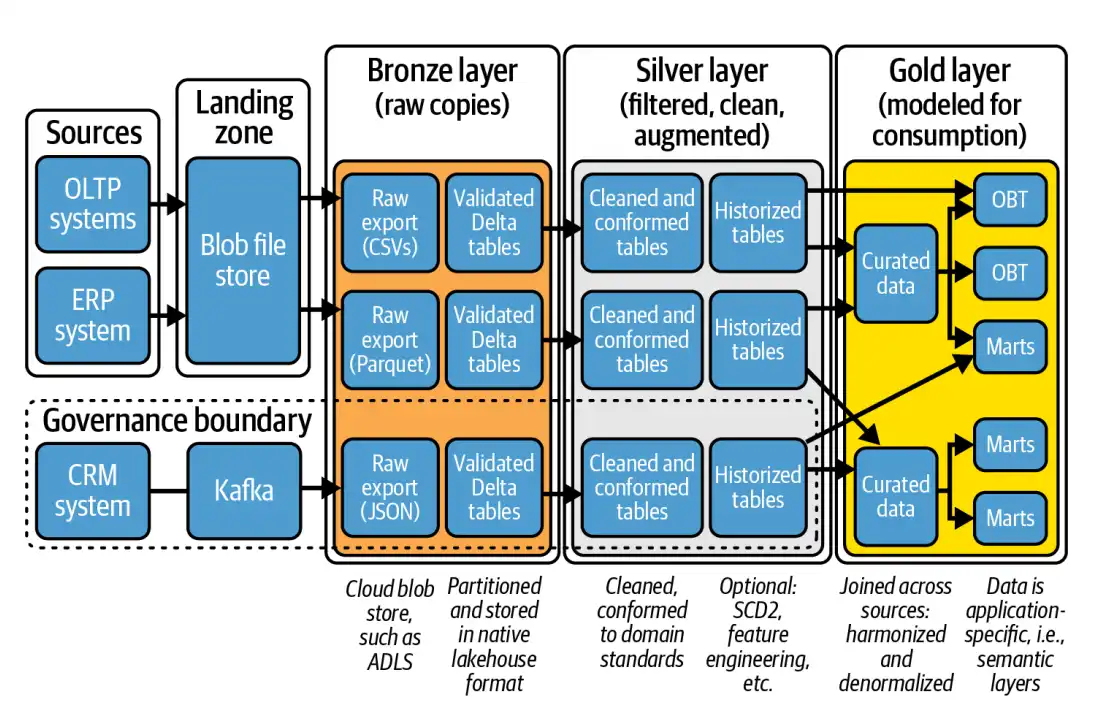
هرچند یادگیری و تسلط بر این تنوع مدلها ممکن است چالشبرانگیز باشد، اما در نهایت کاربران داده از این انعطافپذیری سود خواهند برد. چرا که میتوانند متناسب با نیاز خود، بهترین نوع دسترسی، تحلیل یا پردازش را انتخاب کرده و به دادههایی قابل اعتماد و متناسب با سطح تخصصی خود دست پیدا کنند، بدون گرفتار شدن در پیچیدگیهای غیرضروری. لایهی Gold اگرچه از نظر ترتیب، آخرین حلقهی زنجیرهی معماری مدالیون است، اما از نظر ارزشی، شاید مهمترین نقش را در تبدیل داده به بینش ایفا میکند. موفقیت این لایه در گرو دو عامل کلیدیست: نخست، طراحی فنی مناسب برای عملکرد بالا، مقیاسپذیری و پاسخگویی به انواع تحلیل؛ و دوم، همسویی دقیق با نیازهای واقعی کسبوکار و اصول حاکمیت داده برای تضمین کیفیت، شفافیت و امنیت.
در این نقطه، میتوان گفت مسیر ما در دل معماری مدالیون، از لایهی خام و دستنخوردهی Bronze تا پالایشیافتهی Silver و در نهایت لایهی ارزشآفرین Gold، روایتیست از پالایش تدریجی داده و آمادگی آن برای تصمیمسازیهای حیاتی. اما قدرت واقعی این معماری صرفاً در لایهبندی آن نهفته نیست، بلکه در انعطافپذیری آن است. سازمانها میتوانند با استفاده از این چارچوب، معماری دادهی خود را با توجه به واقعیتهای عملیاتی، محدودیتهای فنی، توان تیمها، و انتظارات بازار، بازتعریف و تنظیم کنند.
نکتهی کلیدی در موفقیت این معماری، تعریف دقیق نقشها، انتظارات، و مسئولیتها در هر لایه است. فقدان استانداردهای داخلی یا ابهام در مرز لایهها میتواند باعث سردرگمی در مسیر داده، تکرار غیرضروری، و حتی از دست رفتن اعتبار اطلاعات شود. بنابراین ضروری است که سازمانها اصول راهنمای مشترکی را تدوین کرده و اجرای آن را بهطور سازمانیافته تضمین کنند، از اعتبارسنجی دادهها در هر مرحله گرفته تا تعریف واضح نقش تیمهای مختلف در طراحی، توسعه و پشتیبانی از هر لایه.
در نهایت، هیچ مدلی، چه ستارهای، چه OBT، چه Data Vault، در ذات خود کامل نیست. موفقیت در معماری داده نه در انتخاب یک مدل خاص، بلکه در توانایی سازمان برای بازبینی، اصلاح و انطباق مستمر با تغییرات محیطی نهفته است. تنها در این صورت است که داده میتواند به یک دارایی پویا و استراتژیک تبدیل شود؛ و معماری مدالیون، به جای آنکه صرفاً چارچوبی نظری باشد، به ابزاری قدرتمند برای خلق ارزش واقعی بدل میشود.
در پایان
معماری مدالیون، صرفاً یک الگوی فنی برای سازماندهی دادهها نیست؛ بلکه تجسمی از یک طرز تفکر است، تفکری که به داده نهتنها بهعنوان مجموعهای از رکوردهای قابل پردازش، بلکه بهمثابه یک دارایی زنده، پویا و وابسته به زمینه نگاه میکند. سفری که از Extra Landing Zone و Bronze آغاز میشود، در Silver پالایش مییابد، در Gold به بینش تجاری تبدیل میشود، و در Serving Layer به دست مصرفکنندهی نهایی میرسد، در واقع بازتابیست از یک چرخهی یادگیری سازمانی که در آن دادهها، سیاستها، فناوریها و انسانها در تعاملند. اما نکتهی کلیدی اینجاست که موفقیت در پیادهسازی این معماری، در گرو درک درست و مشترک از نقشها، مرزها، و تعامل بین لایههاست. هیچ استاندارد جهانی یا راهحل واحدی وجود ندارد؛ هر سازمان باید با توجه به منابع، فرهنگ فنی، پیچیدگی دادهها و اهداف کسبوکار خود، نسخهی مختص به خود را از این معماری طراحی کند. اگرچه ابزارها، چارچوبها و پلتفرمها تغییر میکنند، اما اصول زیربنایی معماری داده پایدار میمانند: سادگی، انعطافپذیری، قابلیت مقیاس، و همراستایی با نیاز واقعی. معماری مدالیون در بهترین حالت خود، نه فقط دادهای پاک و مدلسازیشده، بلکه دانشی قابل اطمینان برای تصمیمگیری فراهم میکند. و در زمانی که سازمانها با هجوم دادهها، فشار تحلیلی، و الزامات انطباقی مواجهند، این معماری میتواند ساختاری بسازد که هم مقاوم باشد، هم چابک، هم دقیق، هم عملی. در پایان، باید گفت: معماری مدالیون نه پایان راه است و نه نسخهای همه منظوره برای همهی چالشهای داده. بلکه بستریست برای حرکت تدریجی از آشفتگی به نظم، از جمعآوری داده به آفرینش ارزش. و این حرکت، همانطور که در این مقاله دیدیم، نیازمند همفکری، بازبینی مستمر، و تعهد به کیفیت است و آن چیزی فراتر از تکنولوژی است: یک فرهنگ دادهمحور.
منبع: مقالهی “طراحی دیتا پلتفرم؛ معماری Medallion” به قلم آقای وحید امیری.